Relaxed Memory Concurrency
内存一致性模型是是系统和程序员之间的规范,它规定了在一个共享存储器的多线程程序中的存储访问应该表现出怎样的行为。内存模型由以下两个属性组成:
Memory Ordering
- Load-Load Order:不同地址上的读操作是否会乱序;
- Load-Store Order:读操作和后面另一个地址上的写操作是否会乱序;
- Store-Load Order:写操作和后面的读操作是否会乱序;
- Store-Store Order:不同地址上的写操作是否会乱序;
- Dependent Loads Order:当第二条读操作的地址取决于前一条读操作的结果时,是否会乱序。
Store Atomicity(处理器的写操作是否会被所有处理器看到)
- Load Other’s Store Early && Non-Causality:允许写操作被自己及个别其他处理器先看到,不支持 Causality。写序列可能以不同顺序被多个处理器观察到;
- Load Other’s Store Early && Causality:允许写操作被自己及个别其他处理器先看到,支持 Causality;
- Load Own Store Early:只允许写操作被自己先看到。写序列以相同顺序被多个处理器观察到;
- Atomic Store:所有处理器同时看到写操作。
最符合程序员直觉的是 SC(Sequential Consistency) Model,即所有的线程以交错的方式访问内存,并且在单个线程中访问内存的顺序与代码的执行顺序一致。这意味着,一个线程执行的操作对随后执行的线程可见,并且所有的线程都会看到一个相同的操作顺序。SC 的 Memory Model 属性:
- LL/LS/SL/SS/DL 乱序:不允许;
- Store Atomicity:Load Own Store Early。
在 SC Model 的基础上,逐步放松各个属性的限制,会依次得到各种弱一致性模型,可以统称为 Relaxed Memory Model。
以上内容来自:https://github.com/GHScan/TechNotes/blob/master/2017/Memory_Model.md
本文是 CS431 的学习笔记,记录了 Relaxed Memory Model 的 promising semantics 的原理和验证自旋锁实现正确性的例子。
the nondeterminism due to shared memory accesses
在基于共享内存实现的多线程并发程序中,执行结果常常具备大量的不确定性,不确定来源主要有两个:thread interleaving 和 instruction reordering。
thread interleaving
thread interleaving 指的是多线程的 Load/Store 指令交替执行,导致执行结果的不确定性。例如下面这段程序:
1 | |
如果 handle1 线程先执行,那么 X = 1;如果 handle2 线程先执行,那么 X = 2:
1 | |
thread interleaving 产生的不确定性非常容易推断,这也是我们所期望的,通过 thread interleaving 可以显著提高程序的性能。
reordering
reordering 指的是 Load/Store 指令被重排序,导致出现不符合直觉的执行结果。硬件和编译器会执行一些优化,只要不是访问相同的内存位置,任何 Load/Store/RMW 指令都可能会被重排序。例如下面这段程序:
1 | |
假设只存在 thread interleaving:
- 线程2先执行
if FLAG.load() == 1,而此时FLAG = 0,那么就不会执行assert_eq!(DATA, 42),程序运行正常; - 线程1先执行
DATA = 42; FLAG.store(1),然后线程后执行if FLAG.load() == 1,此时FLAG = 1,因此会进行 if 分支执行assert_eq!(DATA, 42),因为DATA = 42已经被执行了,因此断言不会失败,程序继续运行。
可见,如果只存在 thread interleaving,那么上面的程序一定不会执行失败。但是,由于存在 reordering,assert_eq!(DATA, 42) 断言有可能会失败:
- Store hoisting:线程1中的
FLAG.store(1)先执行,然后线程2执行if判断成功,之后执行assert_eq!(DATA, 42)断言就会失败,因为此时DATA = 0; - Load hoisting:线程2中的
assert_eq!(DATA, 42)先执行,此时DATA = 0,因此断言失败,程序崩溃。
我们把硬件/编译器 reordering 导致的 unintended behaviors 统称为 relaxed behaviors,relaxed behaviors 无法在 thread interleaving 语义中观测到。
solution for relaxed behaviors & orderings
可以使用 ordering primitives 禁止 reordering,从而避免出现 relaxed behaviors:
Access ordering:使用
Release/Acquiresynchronization。Fence:在 Store/Load 之间插入
fence(SC);
(1)使用 Release/Acquire synchronization:
1 | |
Release Store:禁止与 Store 之前的指令重排序;Acquire Load:禁止与 LOAD 之后的指令重排序。因此只要 FLAG.load(acquire) == 1,那么 assert(DATA == 42) 断言一定会成功。
(2)使用 fence(SC):
1 | |
SC fence:禁止重排序 SC fence 之前和之后的指令。那么,只要 FLAG.load(acquire) == 1,那么 assert(DATA == 42) 断言一定会成功。
但是 relaxed behaviors & orderings 的精确含义是什么?到底什么行为是被允许的、什么行为是不被允许的?为了推断并发程序的正确性,我们需要为 relaxed behaviors & orderings 找到一个好的语义。
promising semantics
promising semantics 是一种 Relaxed Memory Model,对 relaxed behaviors & orderings 进行建模。它有下面的四个 Key idea:
- modeling load hoisting w/ multi-valued memory:Allowing a thread to read an old value from a location;
- modeling read-modify-write w/ message adjacency:Forbidding multiple read-modify-writes of a single value;
- modeling coherence & ordering w/ views:Constraining a thread’s behavior;
- modeling store hoisting w/ promises:Allowing a thread to speculatively write a value。
multi-valued memory
在 promising semantics 中内存是 location 到 list message 的映射,message 由 value 和 timestamp 组成。因此线程可以从一个 location 读取一个 old value。
multi-values memory 的目的是为 load hoisting 建模,例如 Load hoisting(r1=r2=0 allowed by reading old values from X and Y):

假设线程1先执行 X = 1,插入一条 X = 1 的 message:

线程2执行 Y = 1,插入一条 Y = 1 的 message:
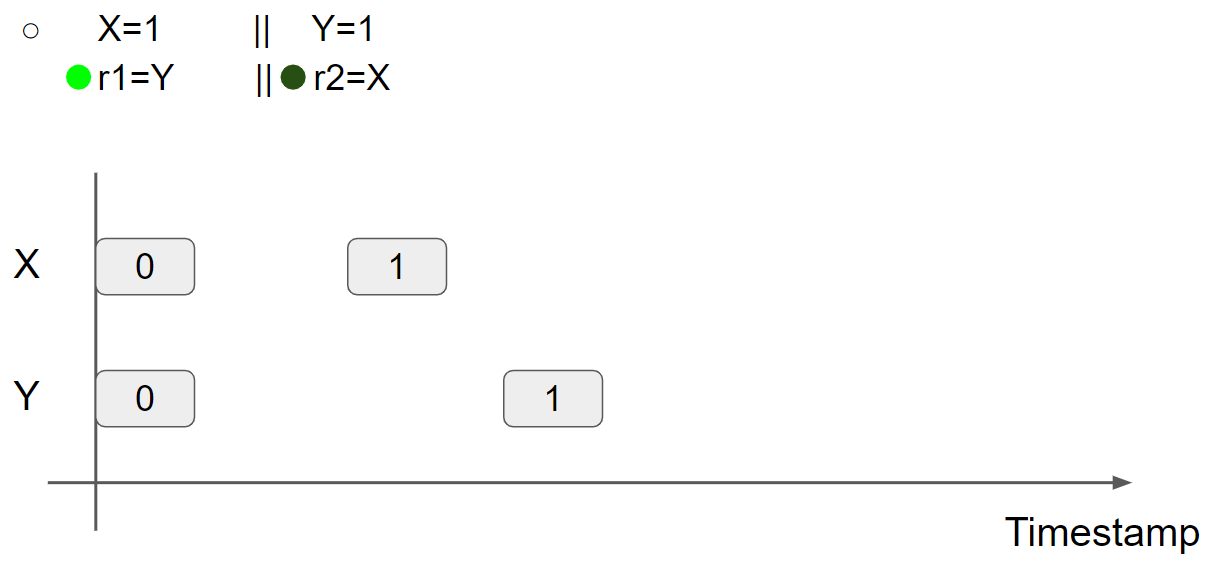
线程1执行 r1 = Y,可以读到 Y = 0 message,因此 r1 = 0:
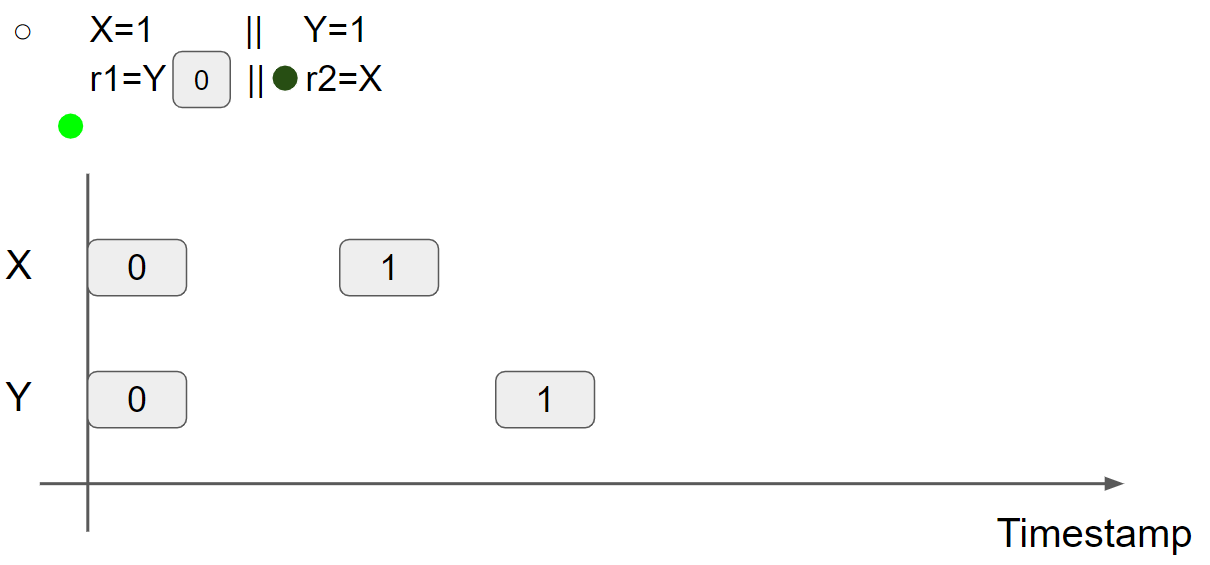
线程2执行 r2 = X,可以读到 X = 0 message,因此 r2 = 0:
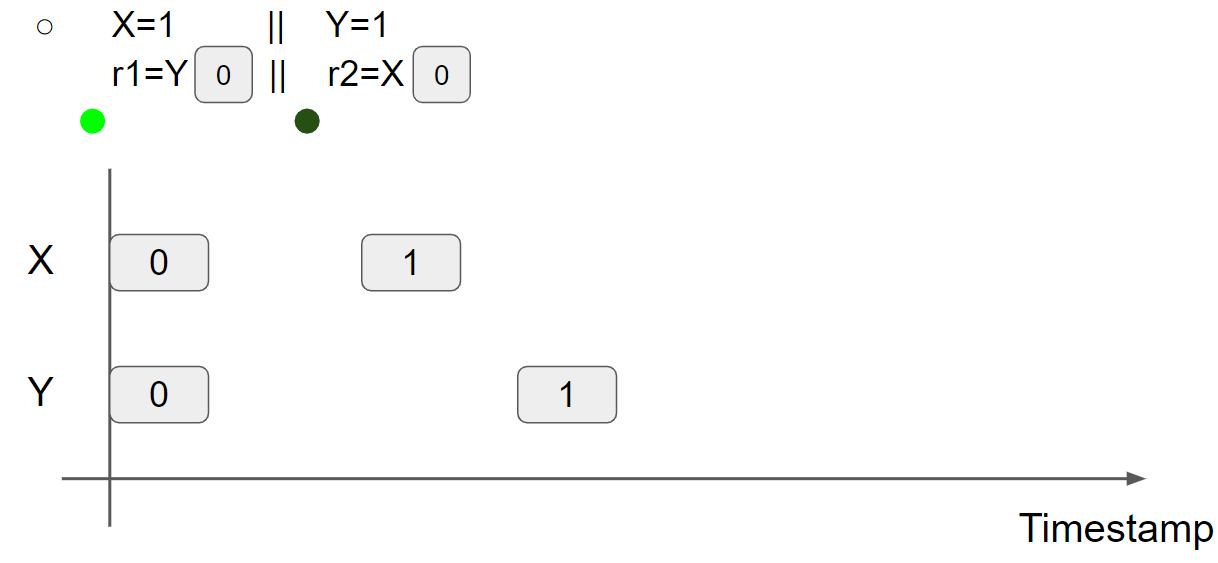
综上所述,在 multi-value memory 中,从 X 和 Y 中可以读取 old value,r1 = r2 = 0 是可以出现的。
从 reordering 的角度考虑,线程1中的 X = 1; r1 = Y 可以被重排序,线程2中的 Y = 1; r2 = X 可以被重排序,因此 r1 = r2 = 0 可以出现,这也被称为 load hoisting。
在 x86 平台中,允许 Store-Load 重排序,因此可以用下面这段真实的程序验证 load hoisting:
1 | |
执行2000000次,发生了1次重排序:
1 | |
message adjacency
为了对 read-modify-write 指令进行建模,需要对 message 增加限制,在 multi-value memory 中 message 的 timestamp 仅仅只一个点,而在 message adjacency 中 message 的 timestamp 具有范围。
message adjacency 对 RMW 指令进行建模,在执行 Read-Modify-writes 指令时,应该把一个新的 message 邻接到旧的 message 右边。例如 counter(r1=r2=0 forbidden):

线程1执行 r1 = X.fetch_add(1),将 X = 1 的 message 邻接到 X = 0 的 message 的右边,此时 r1 = 0:
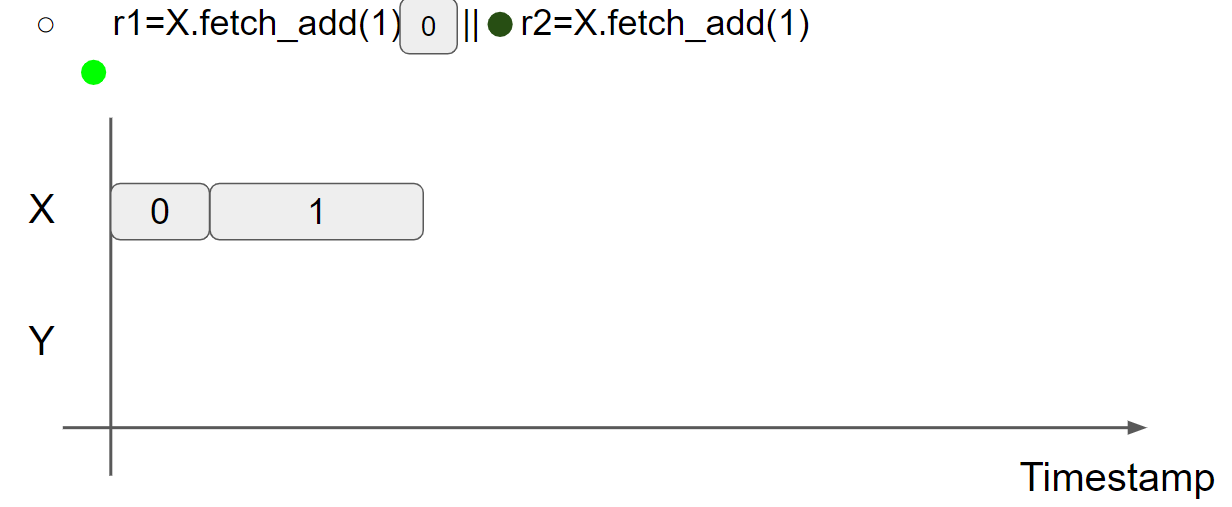
线程2执行 r2 = X.fetch_add(1),因为 X = 0 这条 message 已经被邻接了,因此 X = 2 message 只能邻接到 X = 1 message 的右边,因此只能读到 X = 1 message,此时 r2 = 1:
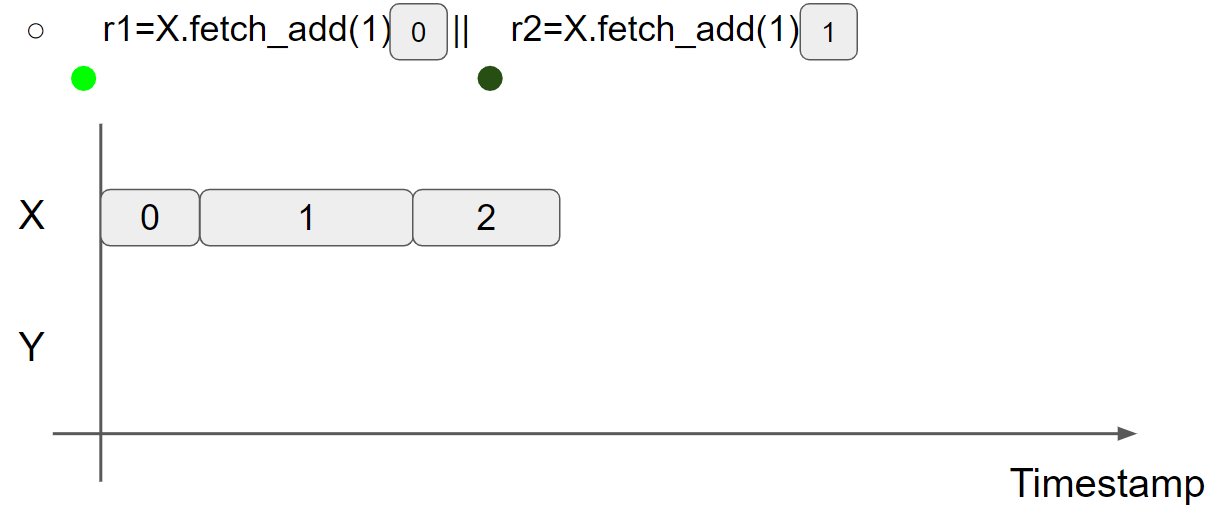
综上所述,r1 = r2 = 0 结果不可能出现,符合 RMW 指令的语义。
views
multi-valued memory 允许太多的 unintended behaviors,当涉及到 coherence 和 synchronization 时需要增加限制。view 是 location 到 timestamp 的映射,表示 message 的确认。一共有三种 view:
- Per-thread view for coherence;
- Per-message view for release/acquire synchronization;
- A global view for SC synchronization。
Per-thread view
Per-thread view 表示一个线程对 message 的确认,要求 reading/writing 发生在当前线程的 view 之后,并且 reading/writing 会改变当前线程的 view。
Per-thread view 用于建模 per-location coherence:
- RR coherence:X=1 || r1=X; r2=X [r1=1,r2=0 impossible]
- RW coherence::r=X; X=1 [r=0]
- WR coherence::X=1; r=X [r=1]
- WW coherence::X=1; X=2 [X=2 at the end]
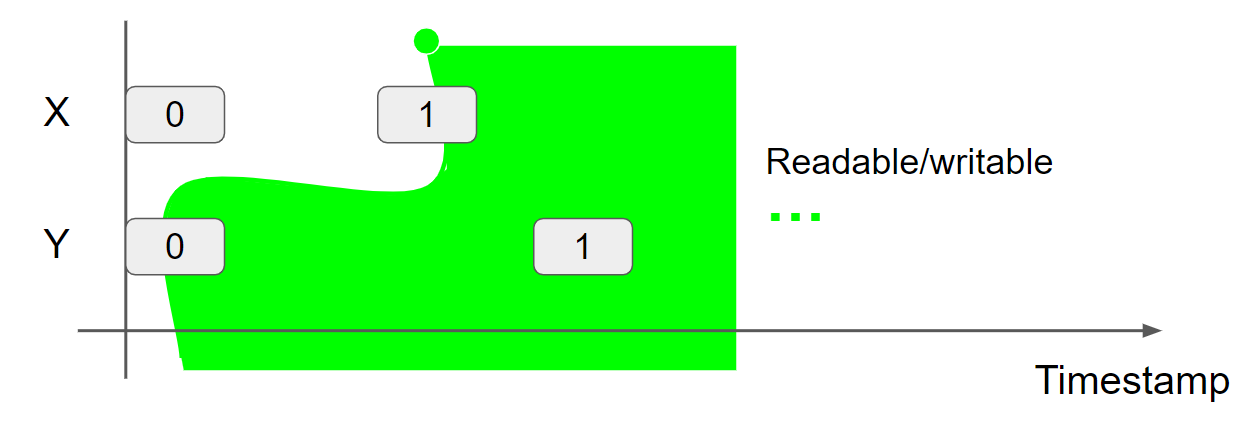
以 WR coherence为例,执行代码 X=1; r=X :初始的线程 view 为 X = 0 & Y = 0,当执行 X = 1 时,会插入一条 X = 1 message,之后线程 view 变为 X = 1 & Y = 0,此时再执行 r = X,由于 reading/writing 只能发生在当前线程的 view 之后,因此一定会有 r = 1。这样就完成了对 WR coherence 的建模。
Per-message view
Per-message view 表示执行 AtomicType.store(T, release) 产生的 released view,用于建模 release/acquire synchronization。例如 message passing (X=1 should be acknowledged after reading Y=1):

线程1执行 X = 1,插入 X=1 message,线程1的视图变为 X = 1 & Y = 0:
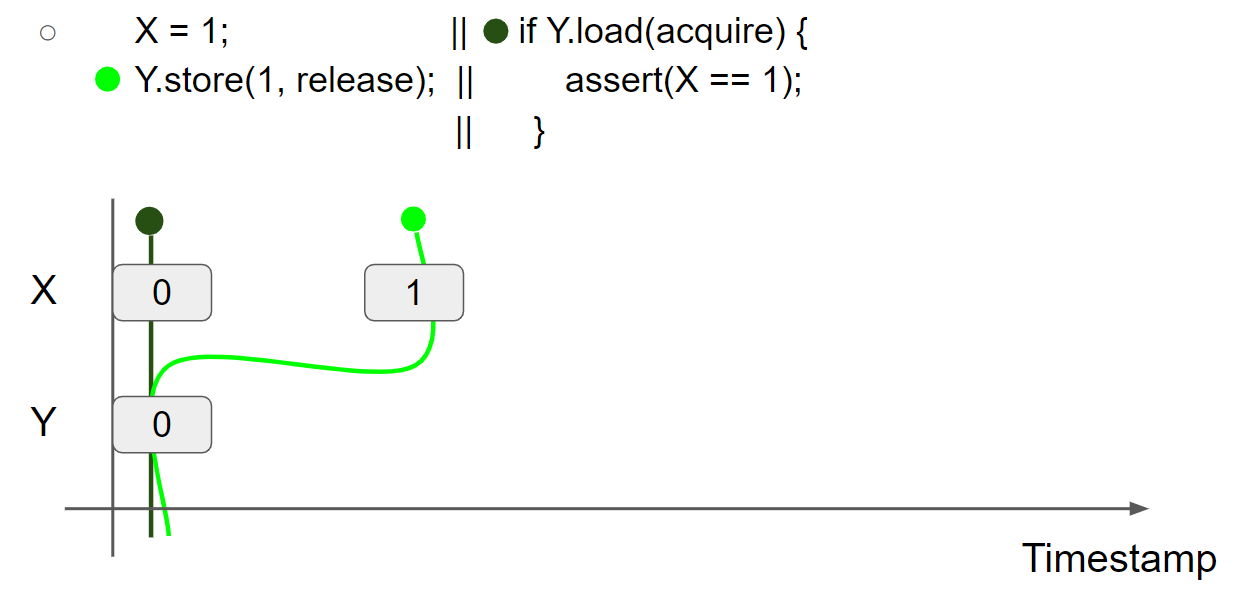
线程1执行 Y.store(1, release),插入 Y=1 message,线程1的视图变为 X = 1 & Y = 1,由于使用了 release,生成了一个 message view:X = 1 & Y = 1:
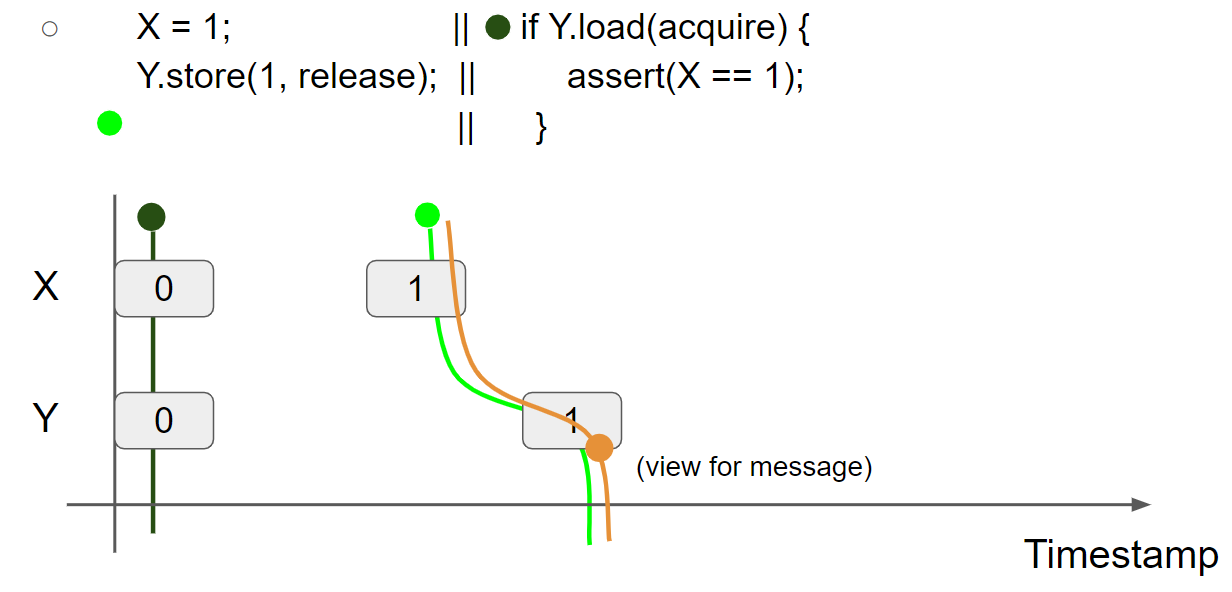
线程2执行 Y.load(acquire),假设线程2读到 Y=1 message,线程2的视图变为 X = 0 & Y = 1,由于使用了 acquire,message view 会合并到线程2的 view 中,因此线程2的视图变为 X = 1 & Y = 1:
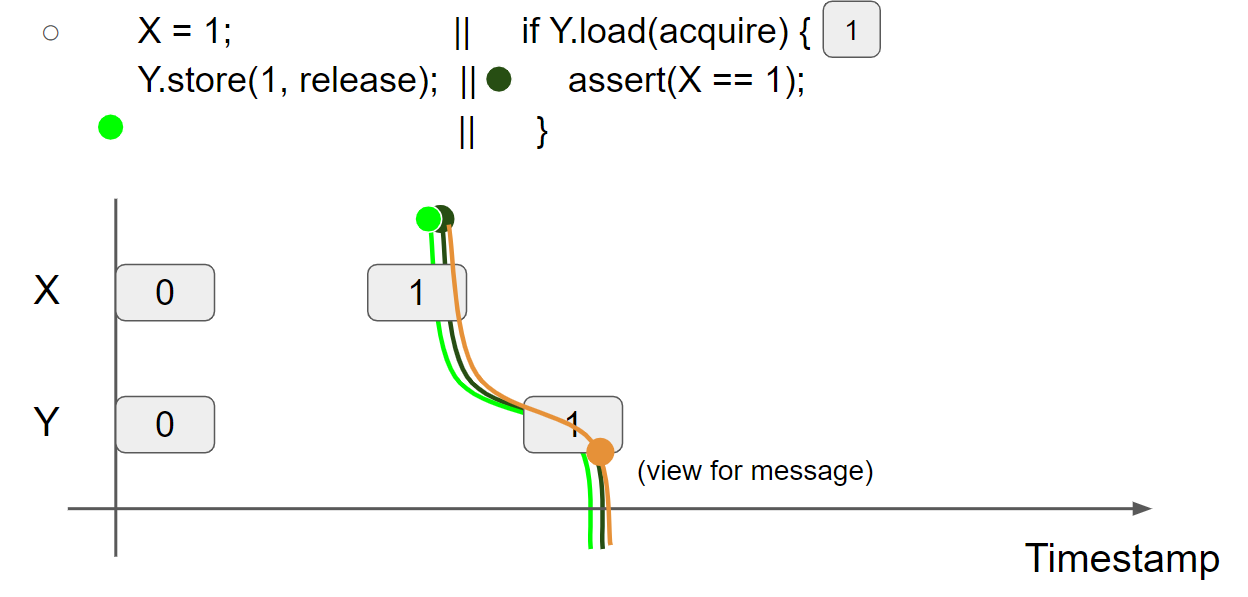
线程2执行 assert(X == 1);,此时线程2的 view 为 X = 1 & Y = 1,因此会读取 X=1 message,断言执行成功:
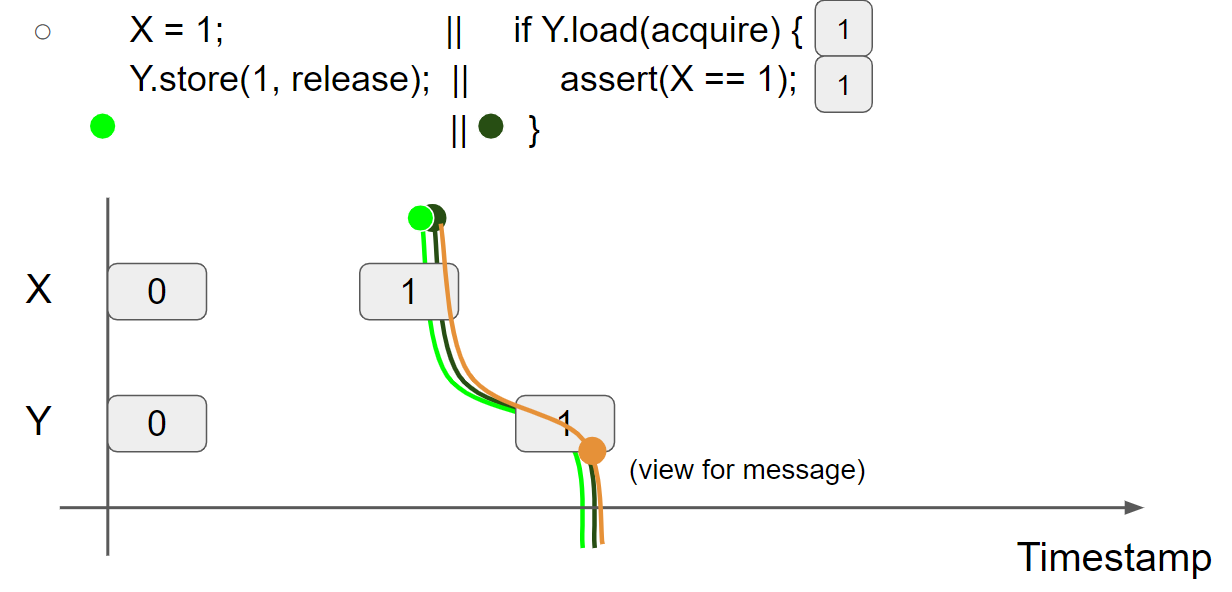
可以看出,通过 Release/Acquire 的使用,可以实现 message 在不同线程之间的传递。
Global view
Global view 表示 SC fence 的当前累积 view,在一个 SC fence 之后,SC view 和 thread view 成为它们之中的最大者。Global view 用于建模 SC-fence synchronization,例如 message passing (X=1 should be acknowledged after reading Y=1):

线程1执行 X = 1,插入 X = 1 message,线程1的 view 变为 X = 1 & Y = 0:
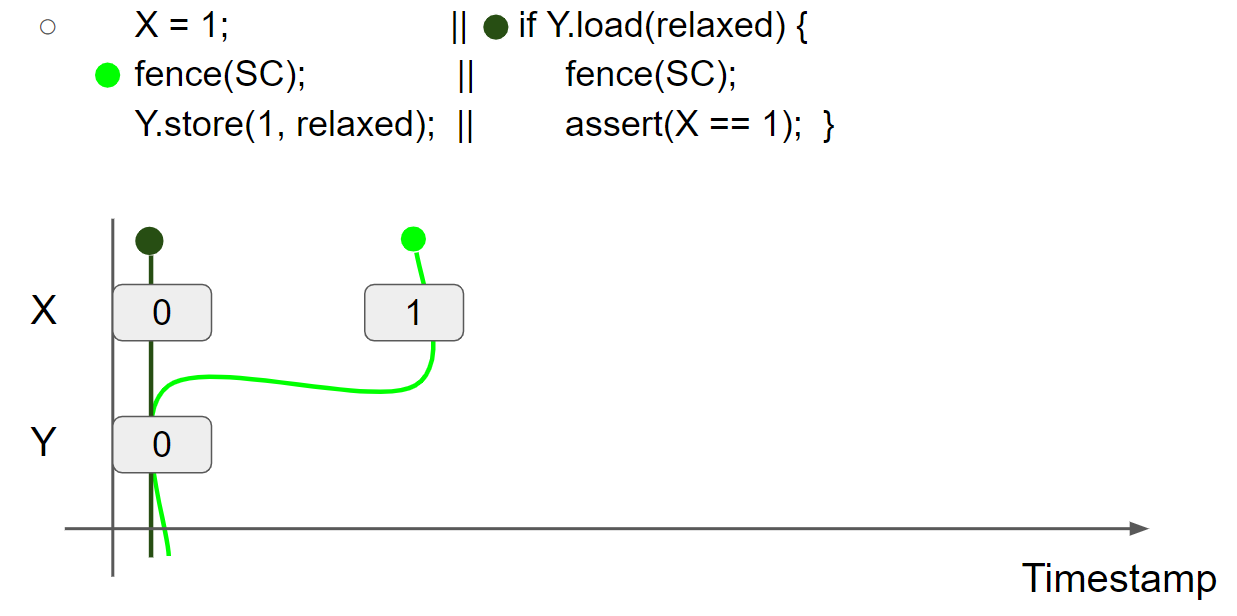
线程1执行 fence(SC),SC view 和 thread1 view 成为它们之间的最大者,因为此时 SC view 不存在,因此 thread1 view 保持不变,SC view 变为 X = 1 & Y = 0:
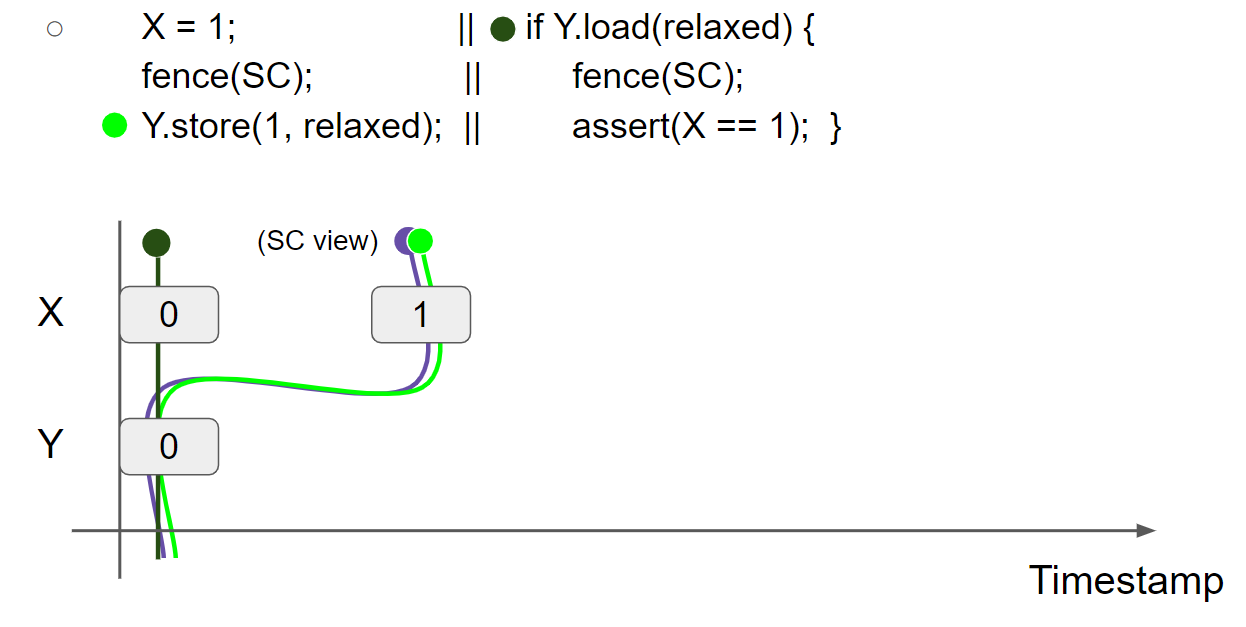
线程1执行 Y.store(1, relaxed),插入 Y = 1 message,线程1的 view 变为 X = 1 & Y = 1:
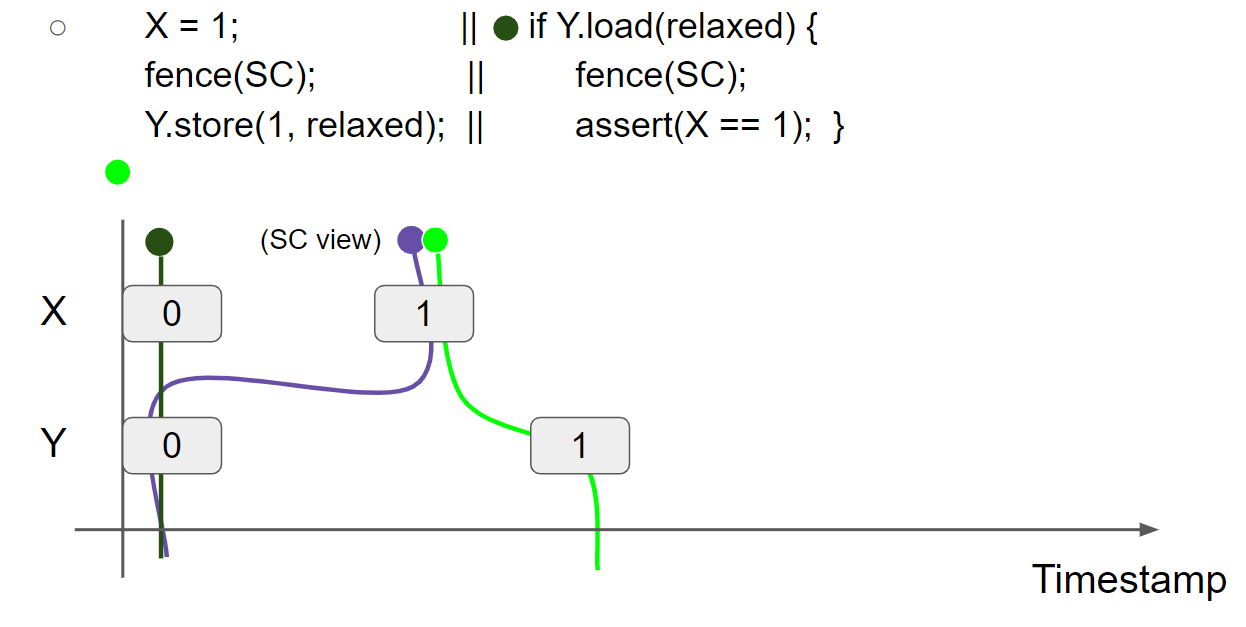
线程2执行 Y.load(relaxed),假设线程2读到 Y = 1 message,线程2的 view 变为 X = 0 & Y = 1:
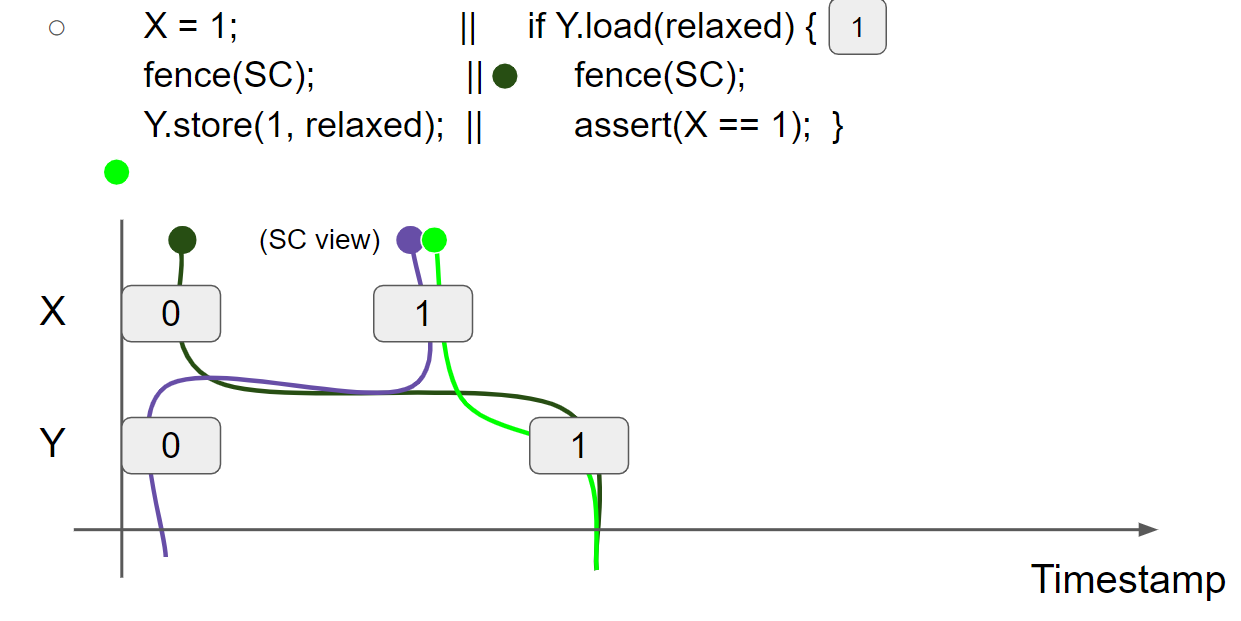
线程2执行 fence(SC),SC view 和 thread2 view 成为它们之间的最大者,因此 thread2 view 变为 X = 1 & Y = 1,SC view 变为 X = 1 & Y = 1:
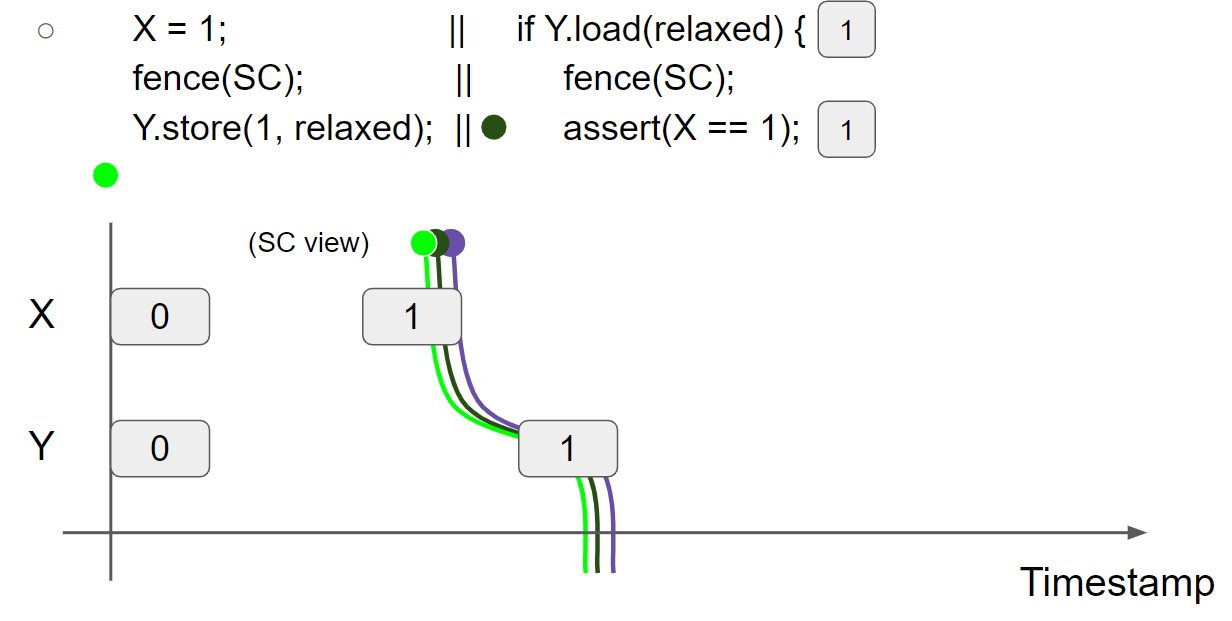
线程2执行 assert(X == 1),此时线程2的 view 为 X = 1 & Y = 1,因此线程2会读到 X = 1 message,断言执行成功。
总结:通过 SC fence 的使用,也可以实现 message 在不同线程之间的传递。
promises
Store hoisting
与 load hoisting、RMW、coherence、synchronization 不同,store hoisting 更为复杂,涉及到以下三种情况:
(1)Store hoisting w/o dependency(r1=r2=1 allowed by reordering in the right)
1 | |
线程2中 X 写入的值不依赖于其他指令,由于 Load-Store reordering,可以观察到 r1 = r2 = 1。
(2)Store hoisting w/ dependency(r1=r2=1 disallowed, “out of thin air” (OOTA))
线程2中 X 写入的值依赖于上一条指令读取的值,此时不允许观察到 r1 = r2 = 1。如果 r1 = r2 = 1,则出现了 OOTA(out of thin air)behavior,那么我们将无法推断并发程序的正确性。
(3)Store hoisting w/ syntactic dependency(r1=r2=1 allowed by compiler opt)
1 | |
从表面上来看,线程2中 X 写入的值依赖于上一条指令,但是if r2 == 1 { X = r2 } else { X = 1 } 无论执行哪个分治都有 X = 1,因此编译器可能会将其直接优化成:X = 1,这样就变成了情况(1)了:
1 | |
优化之后的代码,线程2写入的值不依赖于其他指令,由于 Load-Store reordering,也可以观察到 r1 = r2 = 1。
这里的难点就是,我们需要找到一个好的 semantic model,其允许(1)和(3)但是不允许(2)。
modeling
promises 对 store hoisting 建模:
- Goal: allowing the hoisting of semantically independent writes only
- Idea: “semantically independent writes” are always writable in the future
- Mechanism
- A thread may speculatively write a value (“promise to write”)
- A thread should always be able to write its promises in the future
(1)例一:store hoisting w/o dependency(r1=r2=1 allowed by reordering in the thread 2)

线程2 promise to write X = 1,插入 X = 1 message:

为了验证线程2可以完成 promise write,需要屏蔽掉线程1:
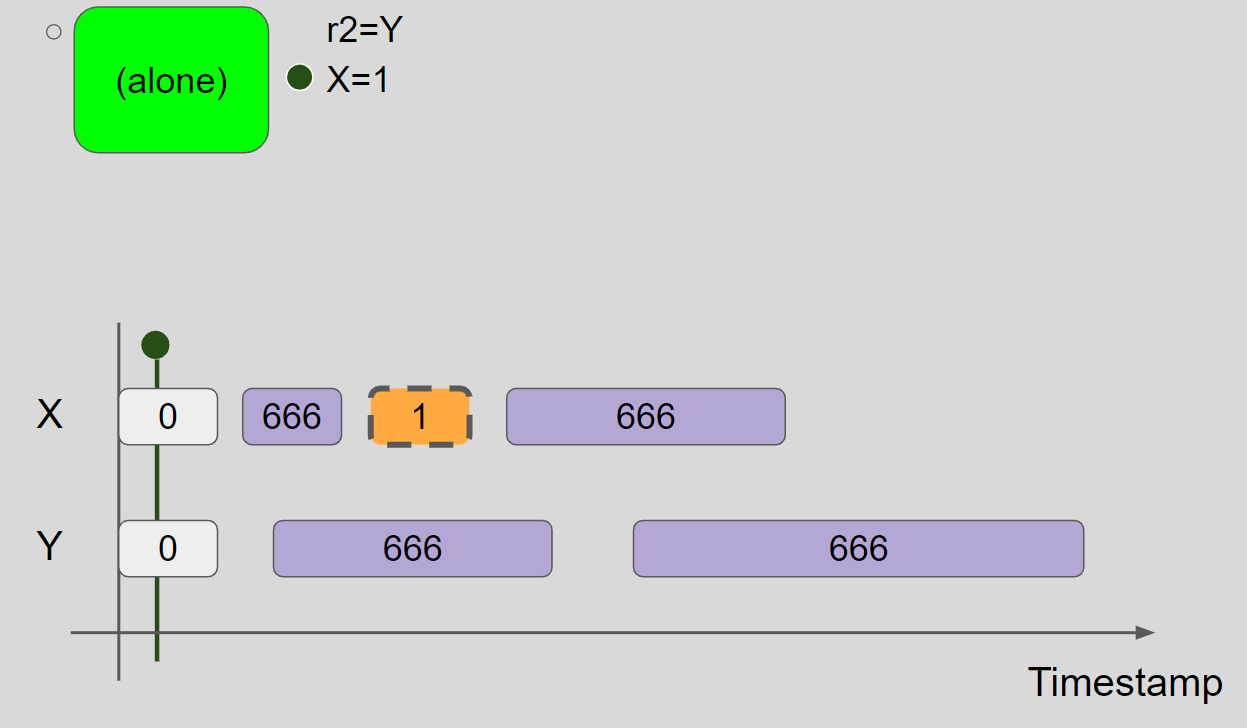
线程2执行 r2=Y,读取 Y = 0 message,线程2视图保持不变。接着,线程2执行 X = 1,插入 X = 1 message,兑现 promise write,线程2的视图更新为 X = 1 & Y = 0:
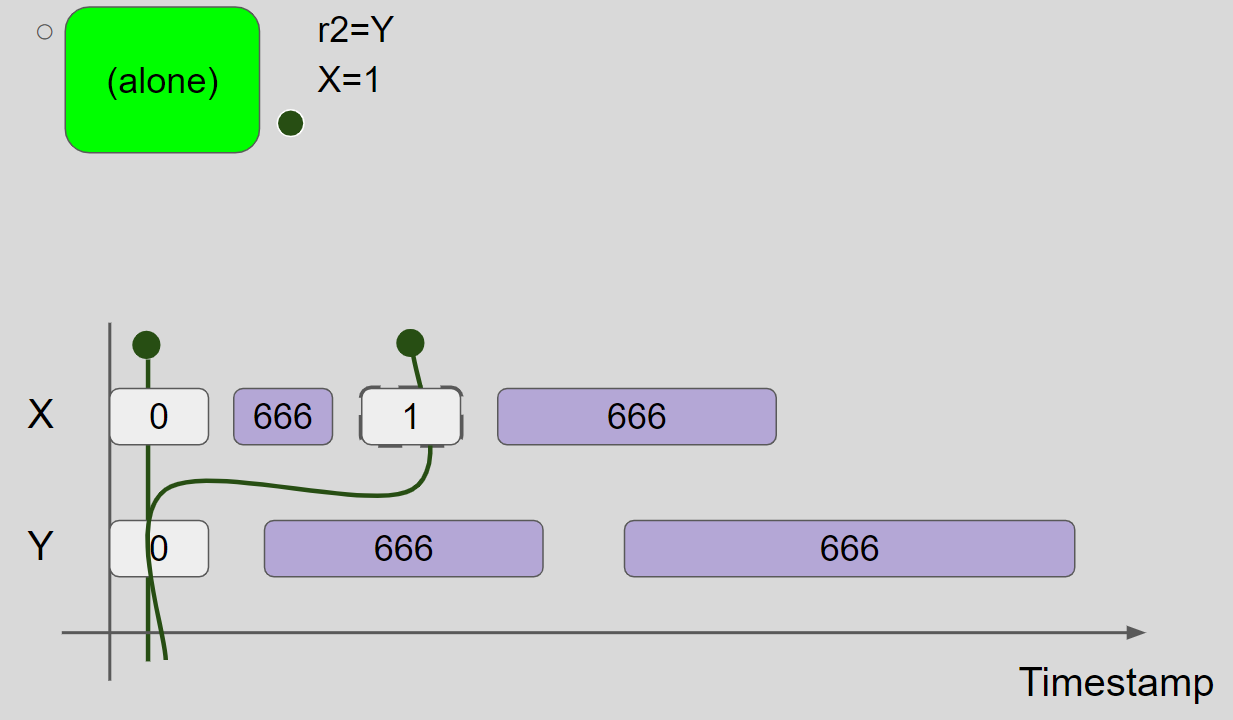
promise write 得到验证,将线程2的视图还原,并将 X = 1 message 标记为 Certified:
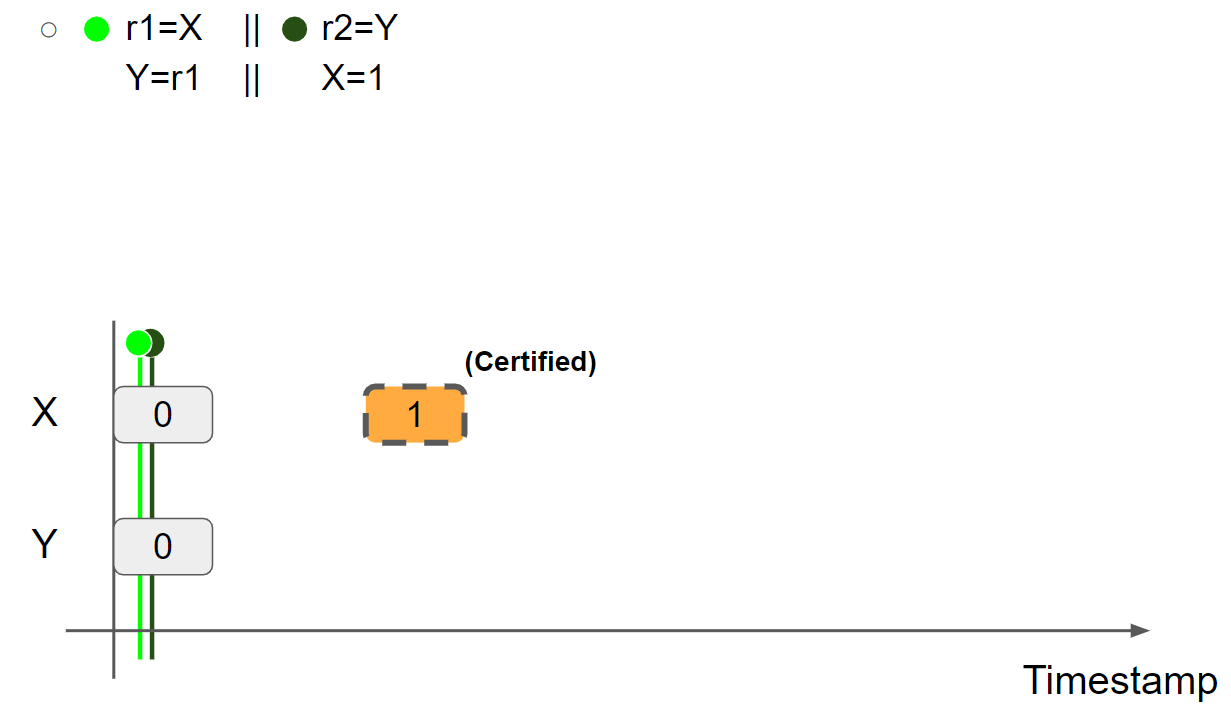
线程1执行 r1 = X,假设读取 X = 1 message,则线程1的视图更新为 X = 1 & Y = 0:
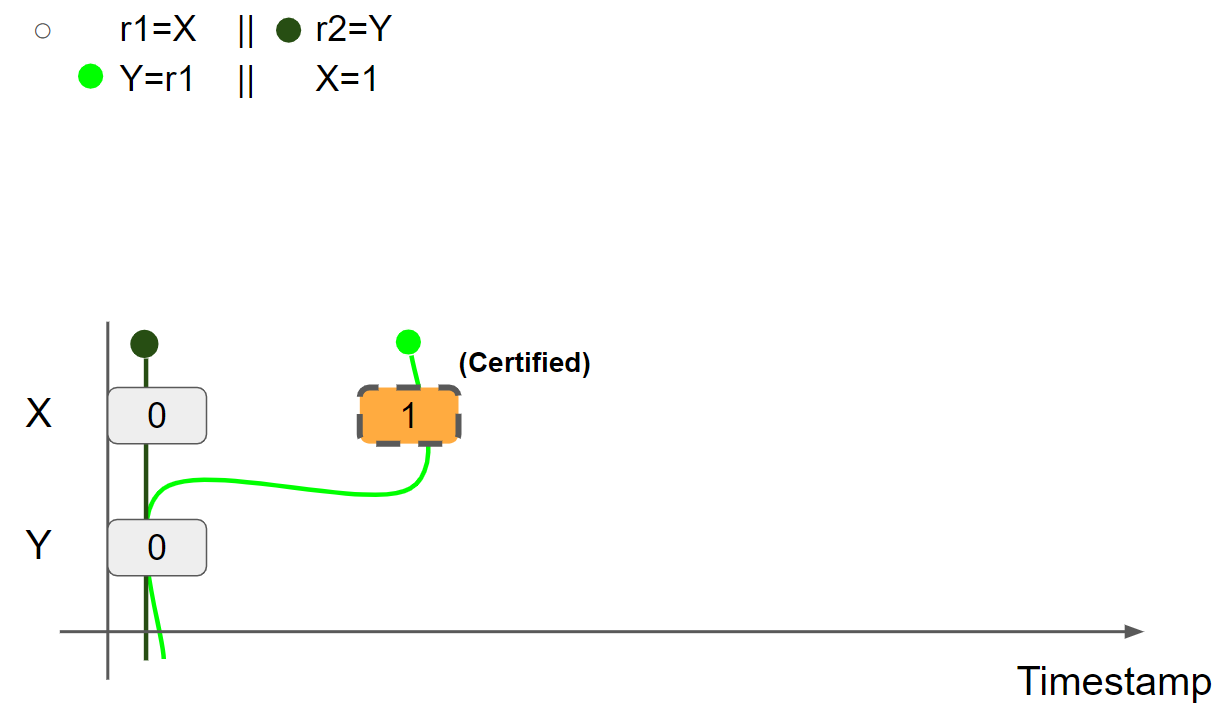
线程1执行 Y = r1,插入 Y = 1 message,线程1的视图更新为 X = 1 & Y = 1:
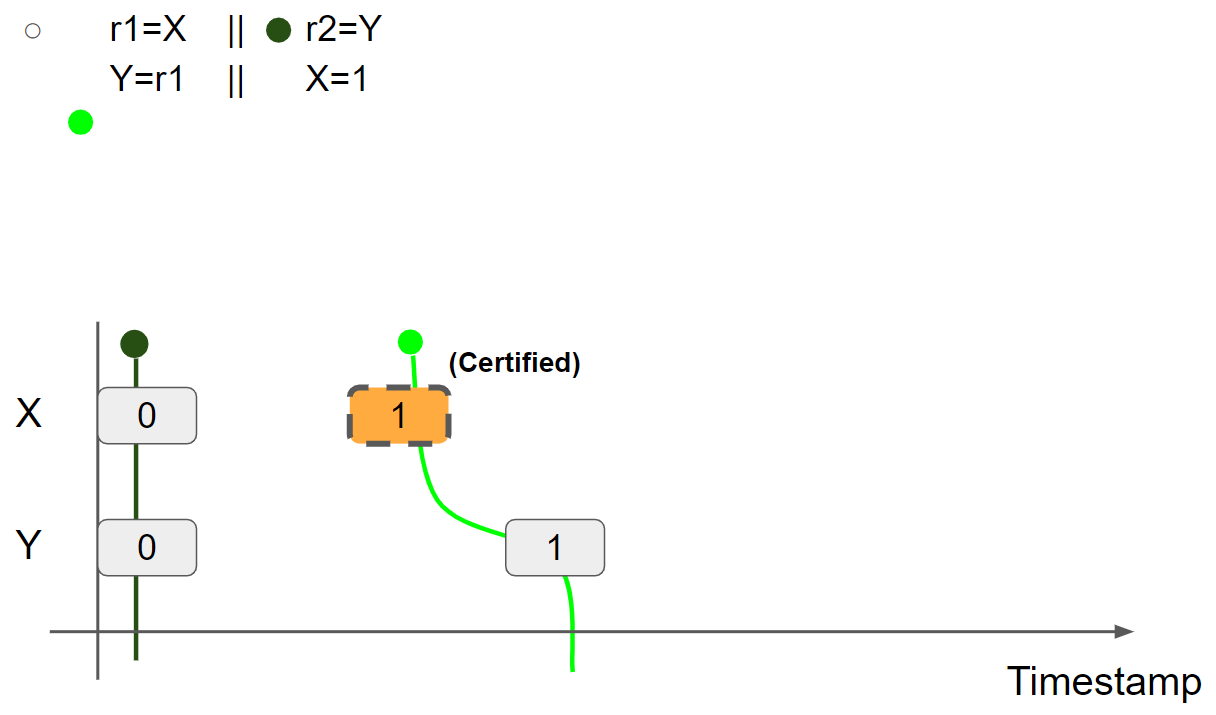
线程2执行 r2 = Y,假设读取 Y = 1 message,则线程2的视图更新为 X = 0 & Y = 1:
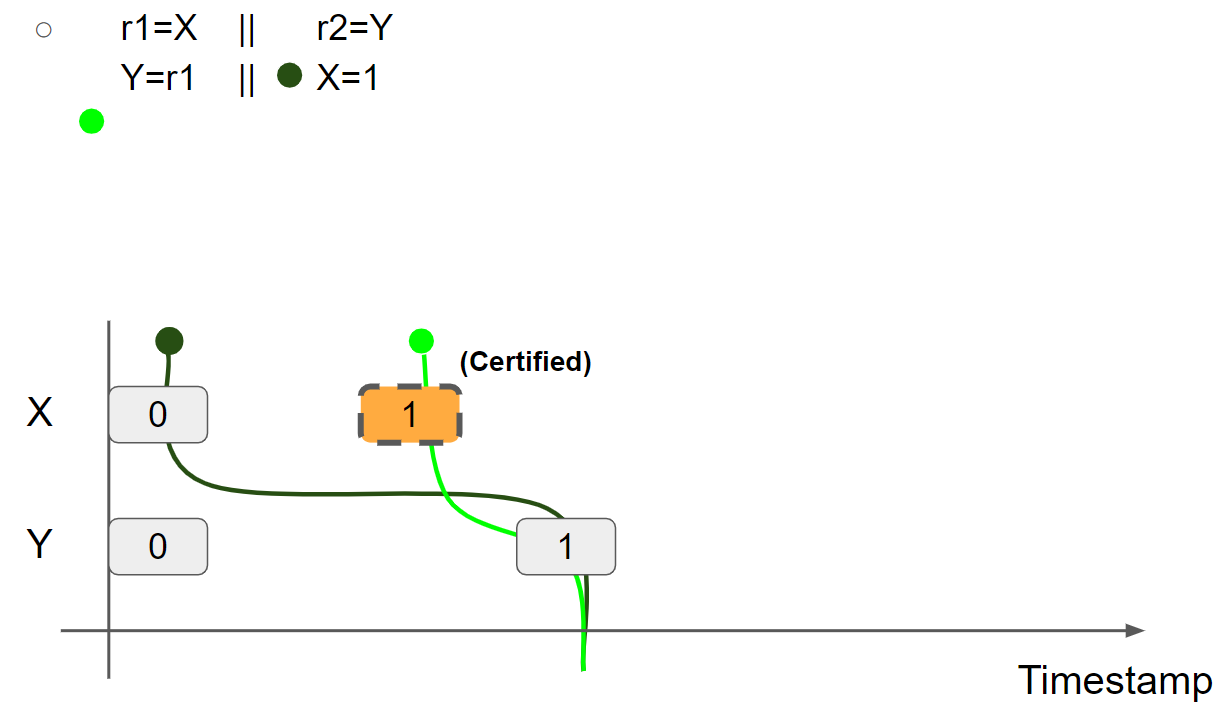
线程2可以执行 X = 1 兑现 promise write,因此 promise 得到二次验证,将 X = 1 message 标记为 Re-Certified:
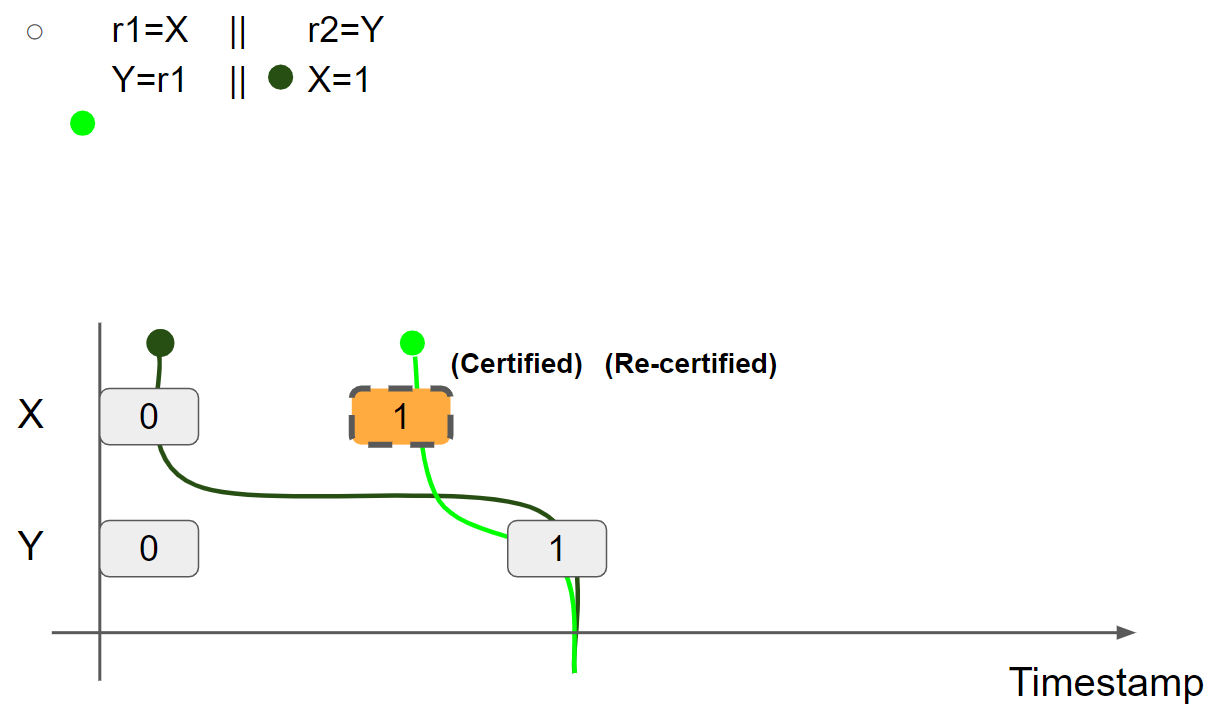
线程2执行 X = 1,兑现 promise write,线程2的视图更新为 X = 1 & Y = 1:
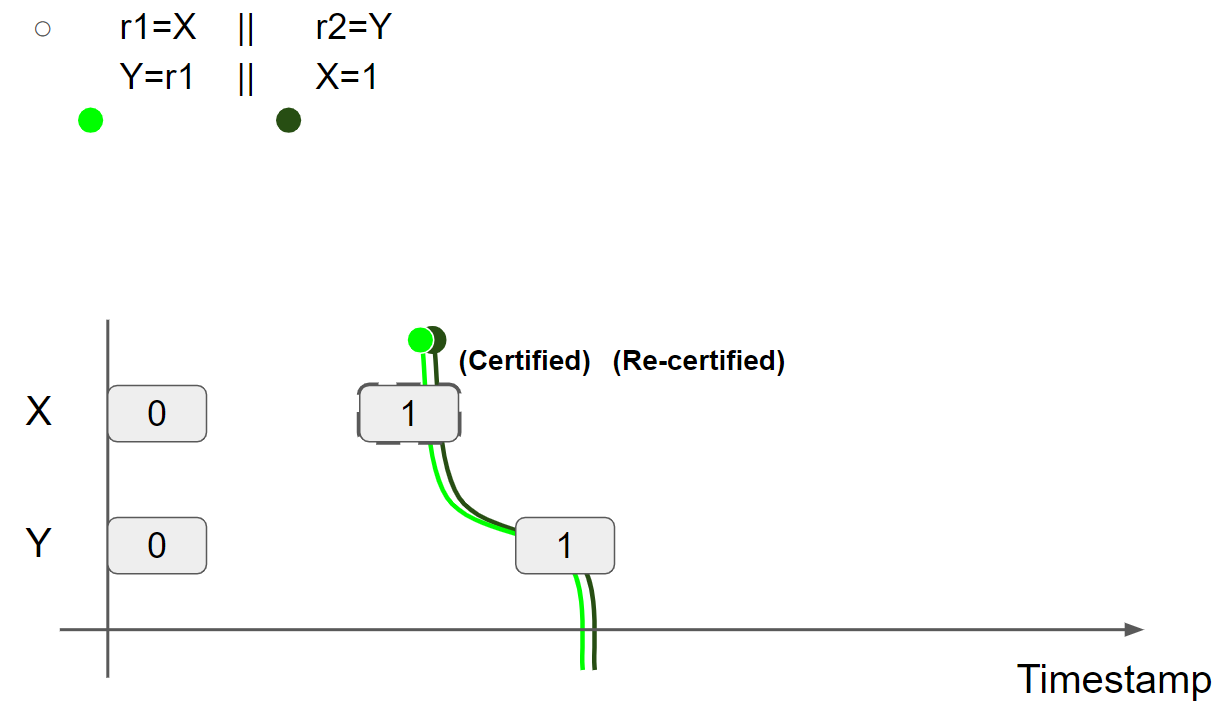
(2)例二:store hoisting w/ dependency(r1=r2=1 disallowed, OOTA)

线程2 promise to write X = 1,插入 X = 1 message。屏蔽线程1,线程2执行 r2 = Y 读取 Y = 0 message,因此 r2 = 0。线程2执行 X = r2,因为 r2 = 0,线程2无法兑现 promise write,执行失败。
因此 r1 = r2 = 1 不可能成立。
(3)例三:store hoisting w/ syntactic dependency(r1=r2=1 allowed)

线程2 promise to write X = 1,插入 X = 1 message:

为了验证线程2可以兑现 promise write,需要屏蔽掉线程1:
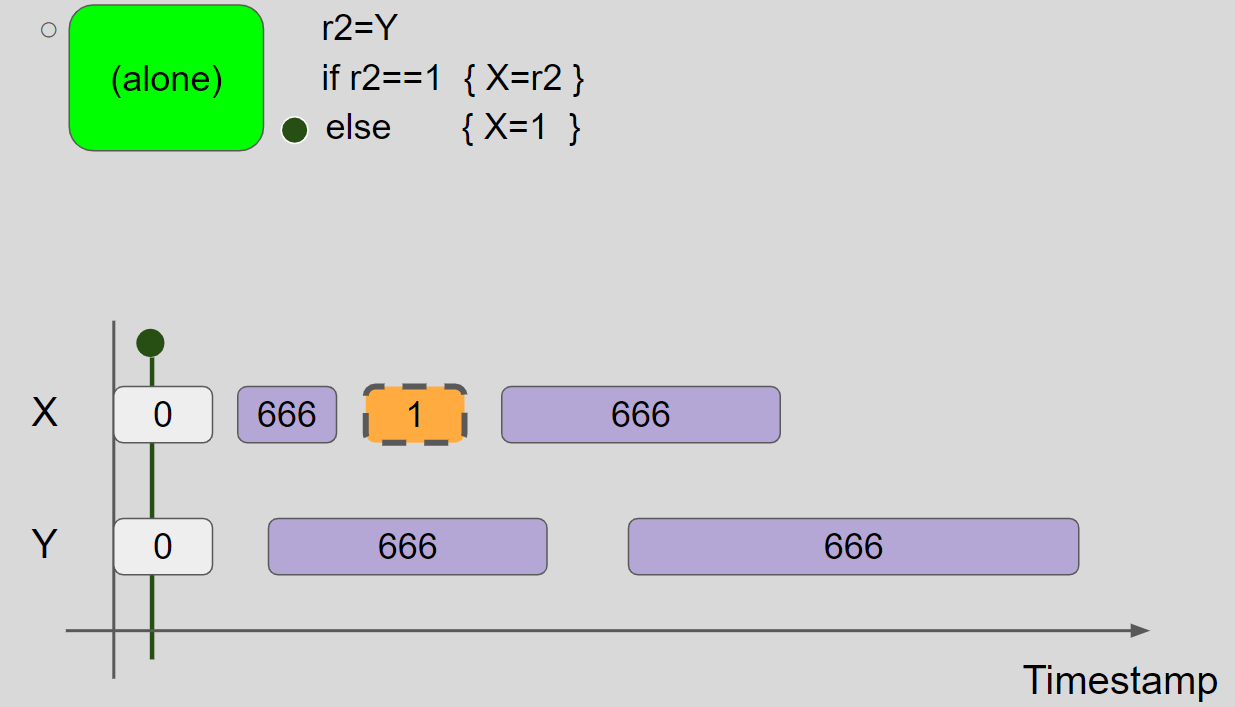
线程2执行 r2=Y,读取 Y = 0 message,线程2视图保持不变。接着,线程2进入 else 分支,执行 X = 1,插入 X = 1 message,兑现 promise write,线程2的视图更新为 X = 1 & Y = 0:
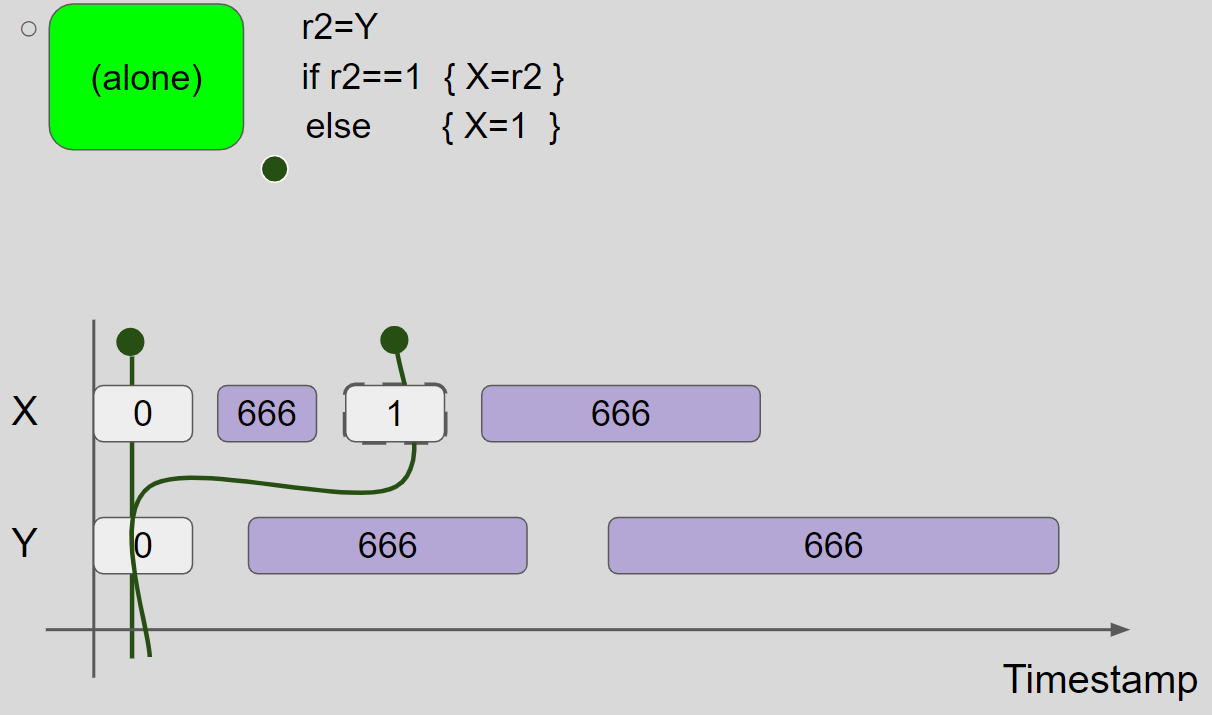
promise write 得到验证,将线程2的视图还原,并将 X = 1 message 标记为 Certified:
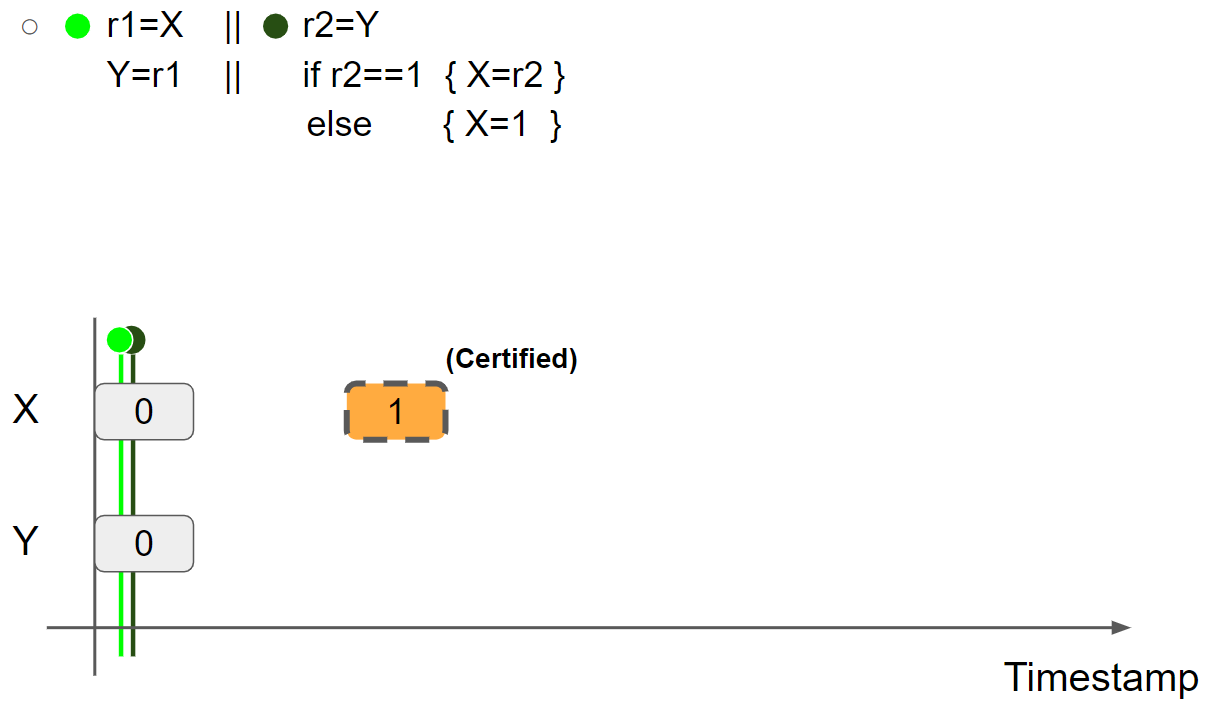
线程1执行 r1 = X,假设读取 X = 1 message,则线程1的视图更新为 X = 1 & Y = 0:
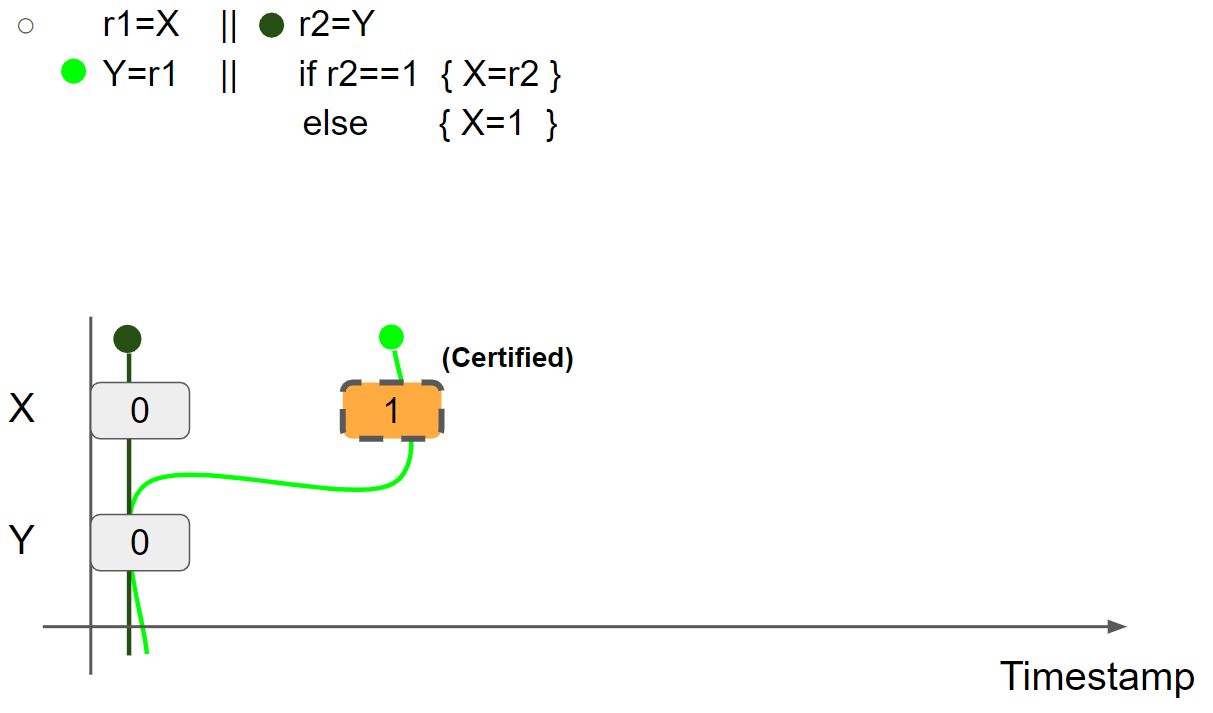
线程1执行 Y = r1,插入 Y = 1 message,线程1的视图更新为 X = 1 & Y = 1:
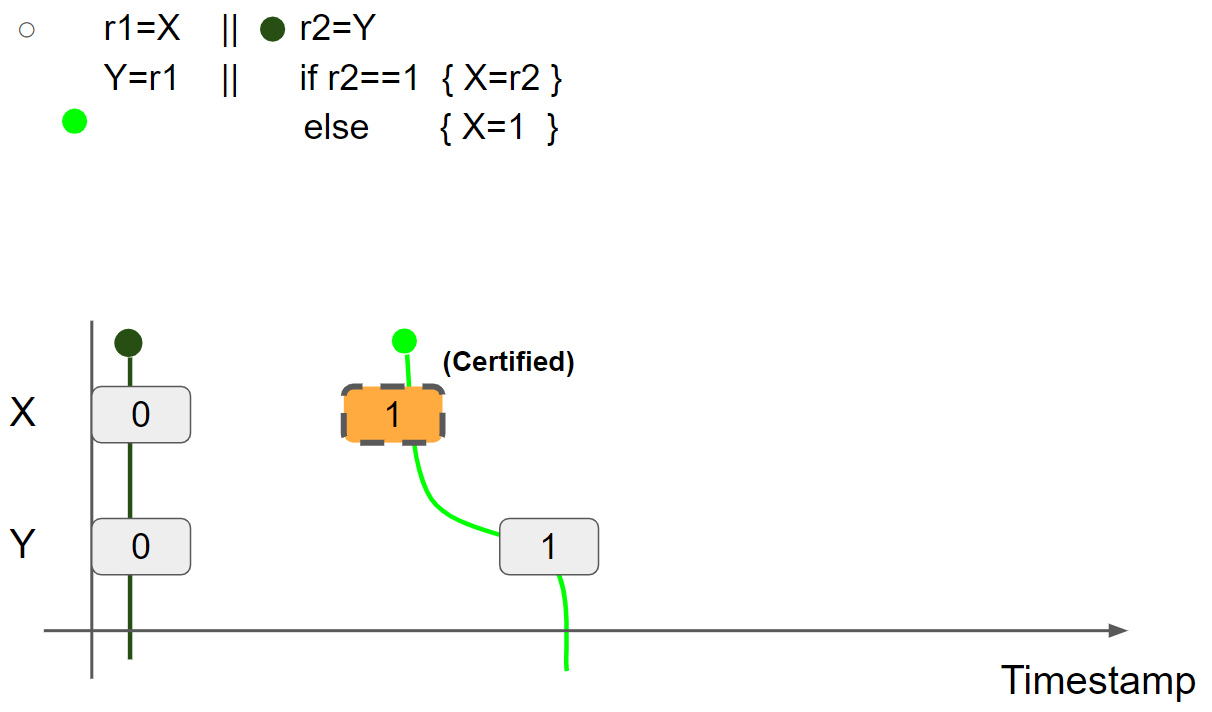
线程2执行 r2 = Y,假设读取 Y = 1 message,则线程2的视图更新为 X = 0 & Y = 1:
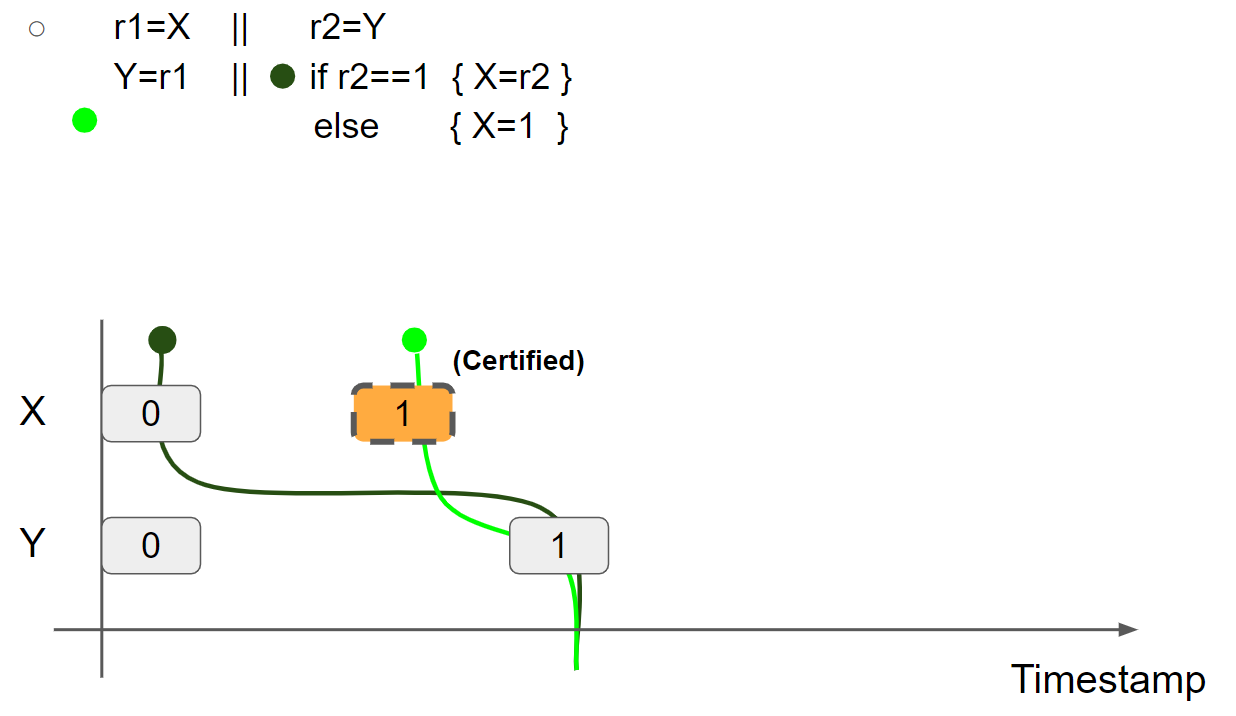
因为 r2 = 1,线程2执行 if r2 == 1 进入 if 分支内部,接着可执行 X = r2 兑现 promise write,因此 promise 得到二次验证,将 X = 1 message 标记为 Re-Certified:
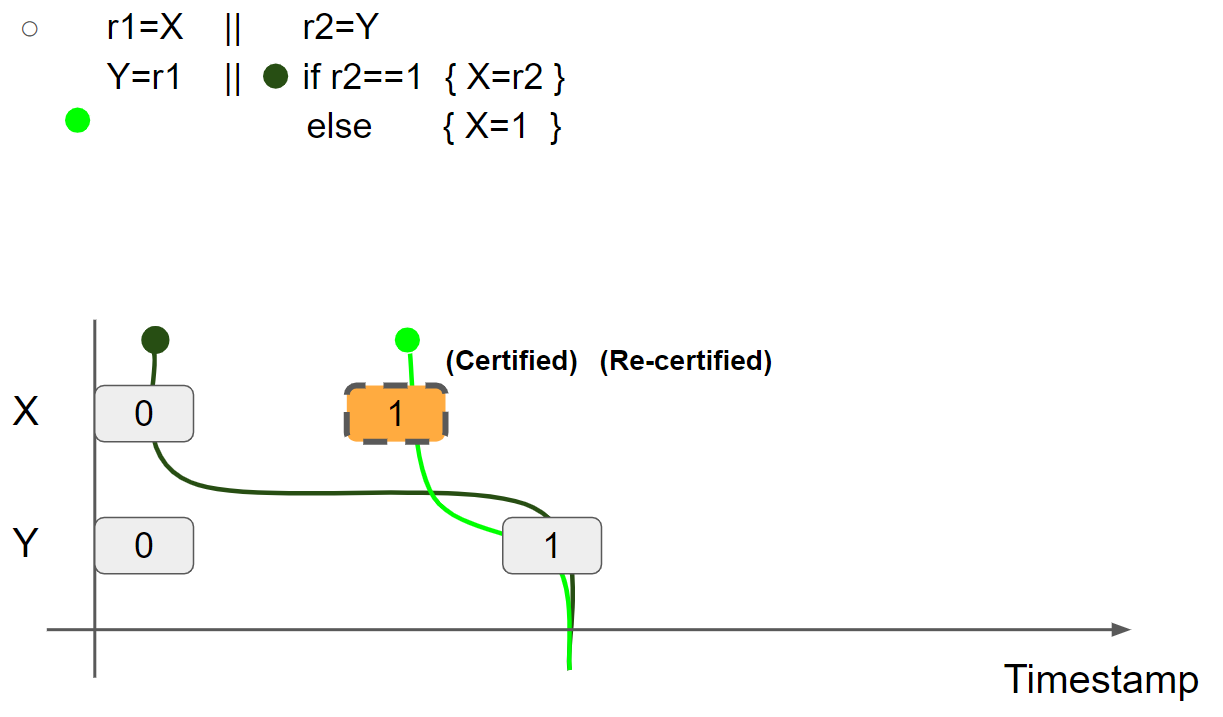
最后,线程2执行 X = r2,兑现 promise write,线程2的视图更新为 X = 1 & Y = 1:
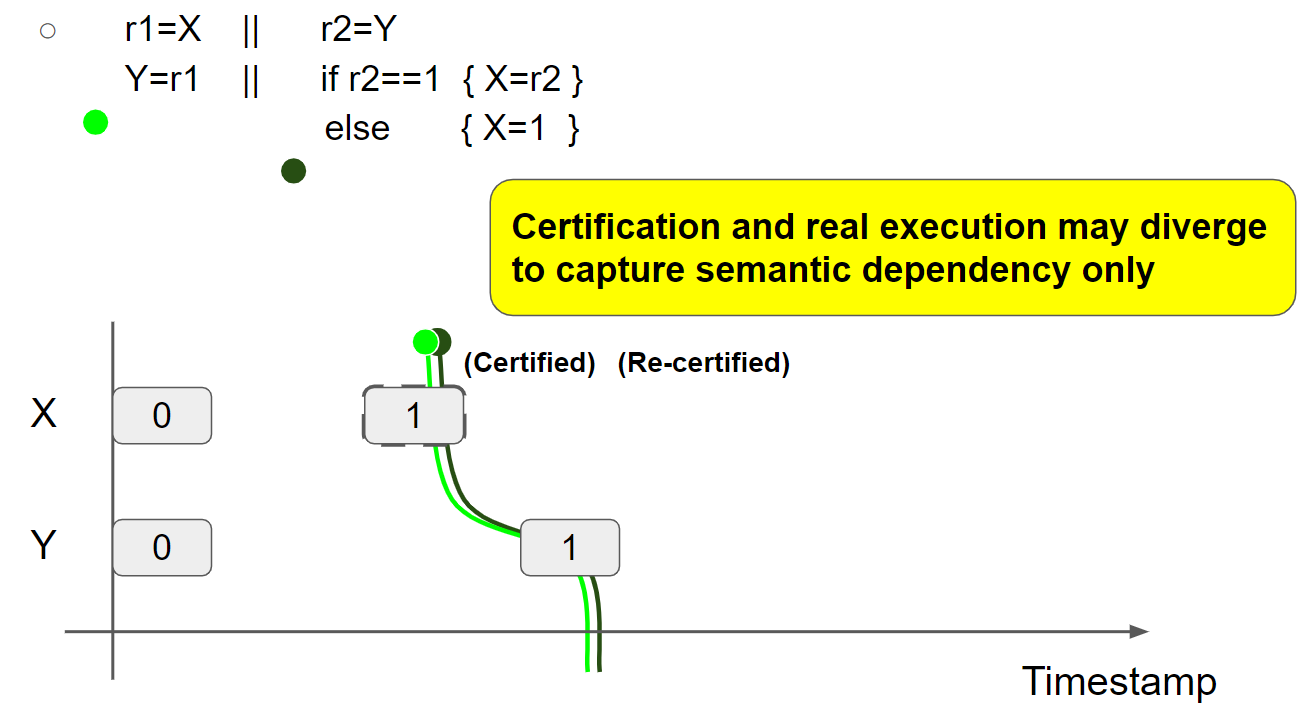
(4)例四:store hoisting w/ syntactic dependency(r1=r2=r3=1 disallowed due to RW coherence)
线程2 promise to write X = 1,并验证 promise(验证过程与前面的例子一致,这里跳过):
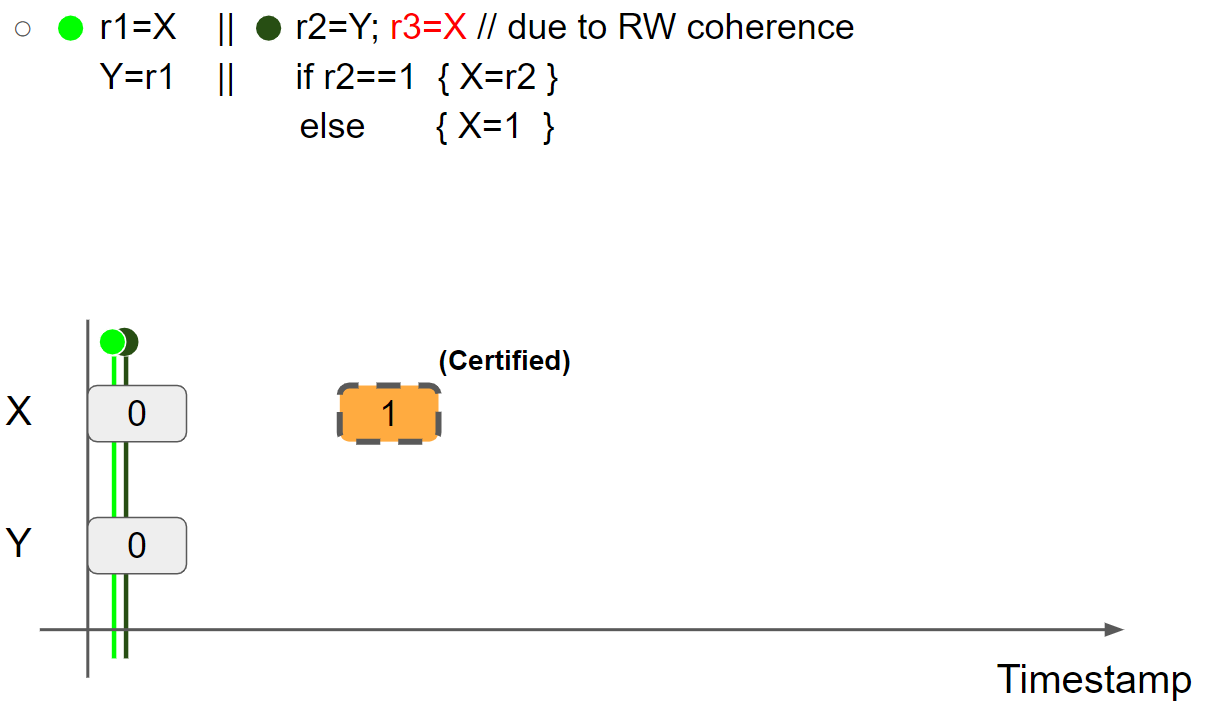
线程1执行 r1 = X,假设读到 X = 1 message,则线程1的视图变为 X = 1 & Y = 0:
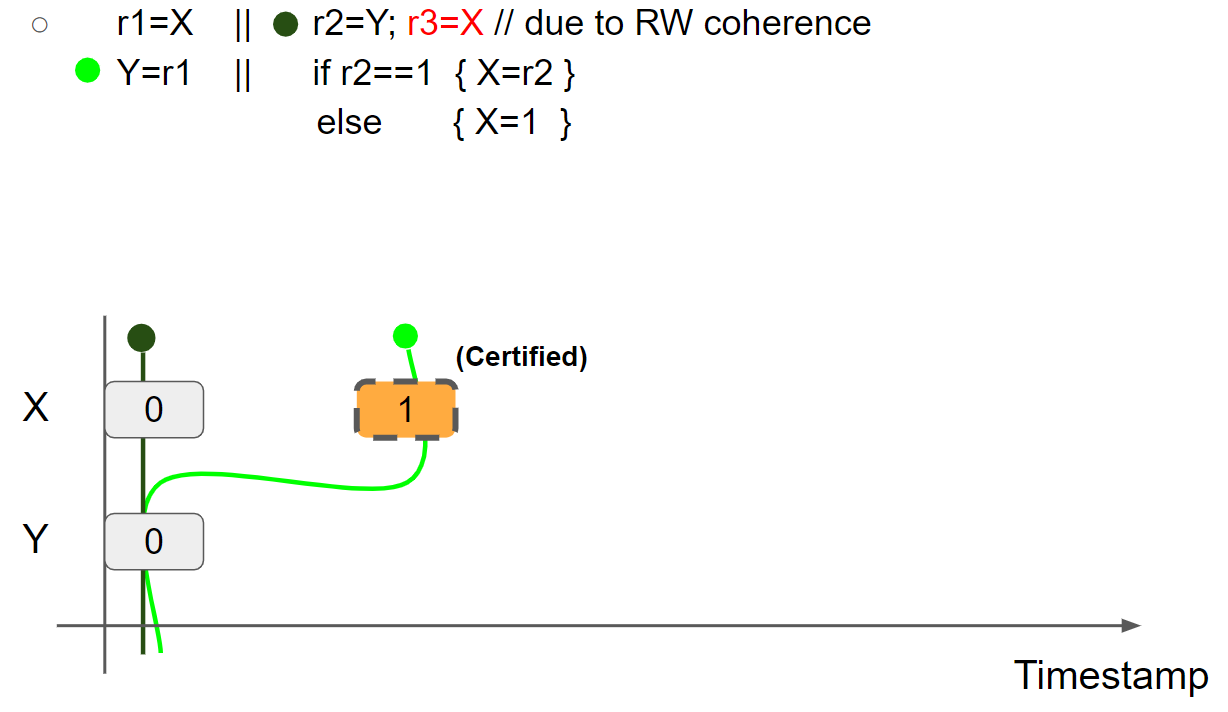
线程1执行 Y = r1,插入 Y = 1 message,线程1的视图变为 X = 1 & Y = 1:
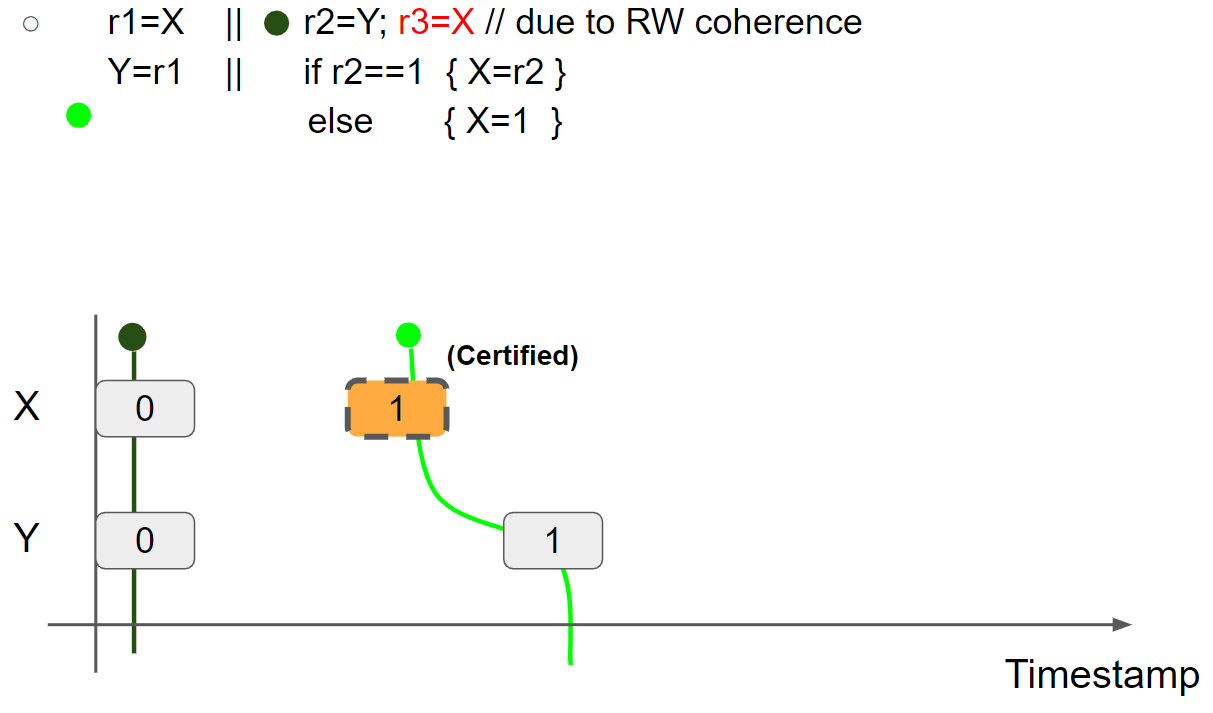
线程2执行 r2=Y,读取 Y = 1 message,线程2的视图变为 X = 0 & Y = 1。接着,线程2执行 r3 = X,假设读到 X = 1 message,则线程2的视图变为 X = 1 & Y = 1:
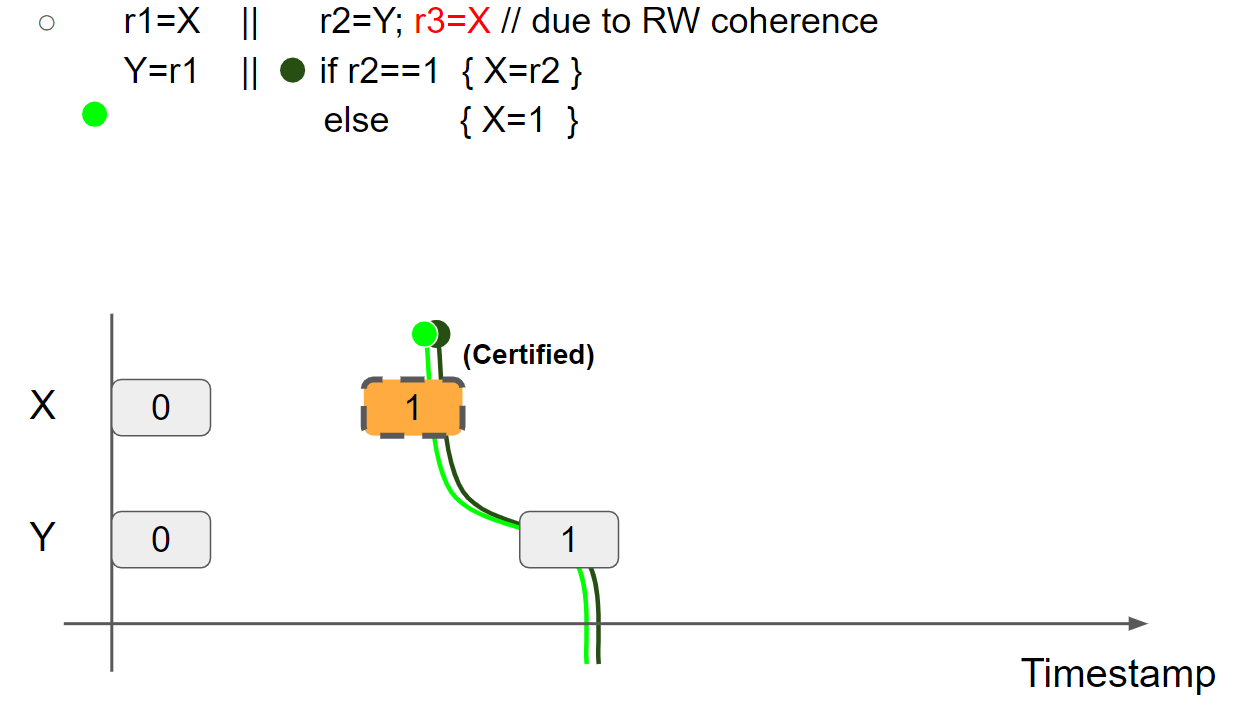
由于 r2 = 1,因此进入 if 分支内部执行 X = r2,由于线程2的视图已经变为 X = 1 & Y = 1,因此只能在当前视图的右边插入新的 X = 1 message,那么就无法兑现 promise write,执行失败:
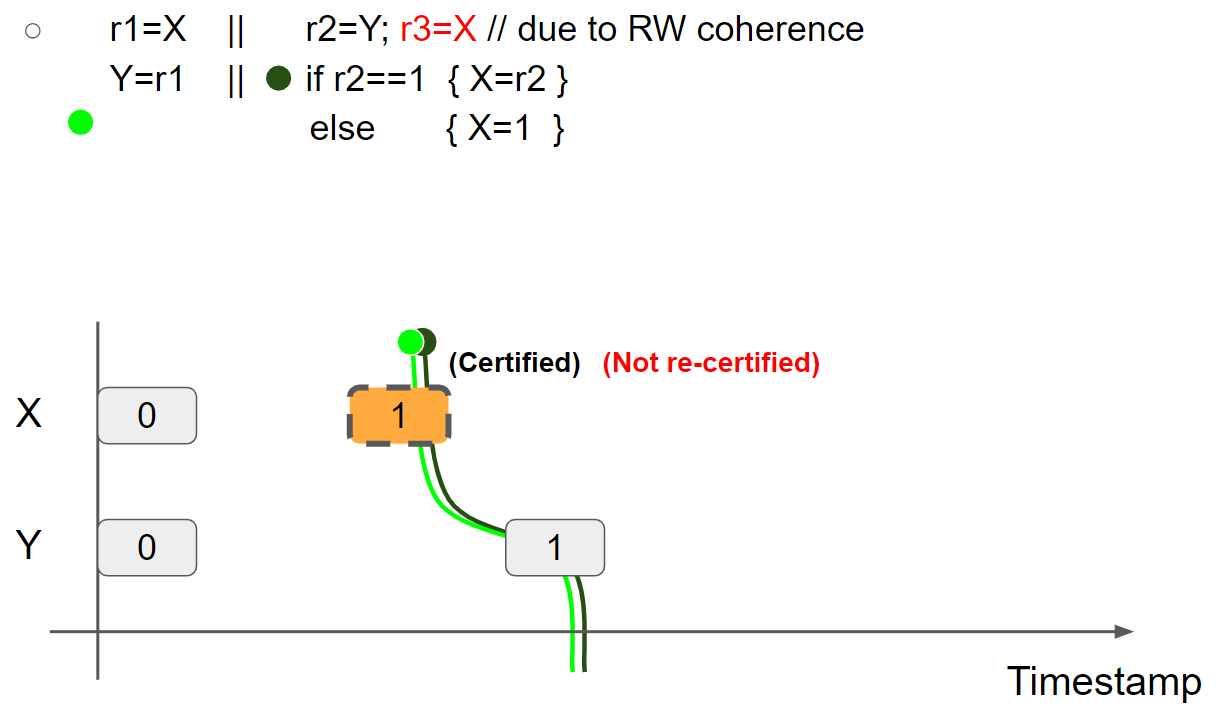
因此 r1 = r2 = r3 = 1 不可能成立。
summary
Promising semantics is an operational semantics modeling relaxed behaviors and orderings.
Key ideas
- Multi-valued memory: modeling load hoisting
- Message adjacency: modeling read-modify-write
- Views: modeling coherence and synchronization
- Promises: modeling store hoisting
examples
Spin lock
Spin lock 代码:https://github.com/kaist-cp/cs431/blob/main/src/lock/spinlock.rs。 关键方法:
1 | |
Lock Guarantee:
- If a lock has already been acquired, lock() will spin.
- Events between lock & unlock are transferred via release/acquire synch.
- When holding the lock, you’ll access the latest value of D (no shared access).
L 表示锁的状态,F 表示锁没有被占用,T 表示锁被占用了。D 表示锁保护的数据。绿色线条表示线程1 view,黑色线条表示线程2 view,黄色线条表示 message view。初始状态下,线程1的 view 和线程2的 view 相同:L = F & D = Something1,message view 为上一个线程是否锁后产生的:

线程1调用 lock 函数获取锁,执行 cas(false, true, acquire) 操作,读取 L = F message,因此 cas 操作执行成功,邻接 L = T message,由于使用了 acquire,message view 会合并到线程1的 view 中,线程1的 view 变为 L = T & D = Something1:
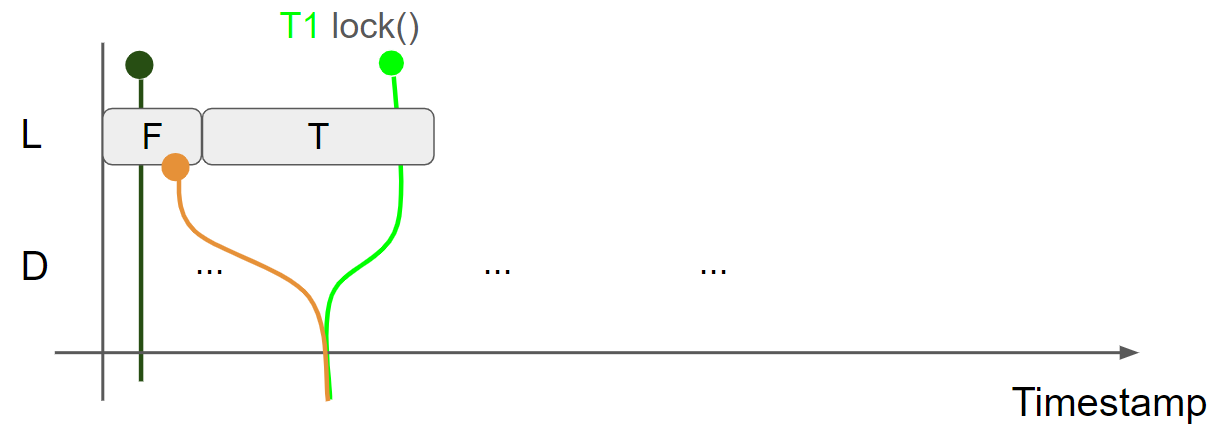
线程1持有锁,并修改 D,插入 D = Something2 message,线程1的view 变为 L = T & D = Something2:
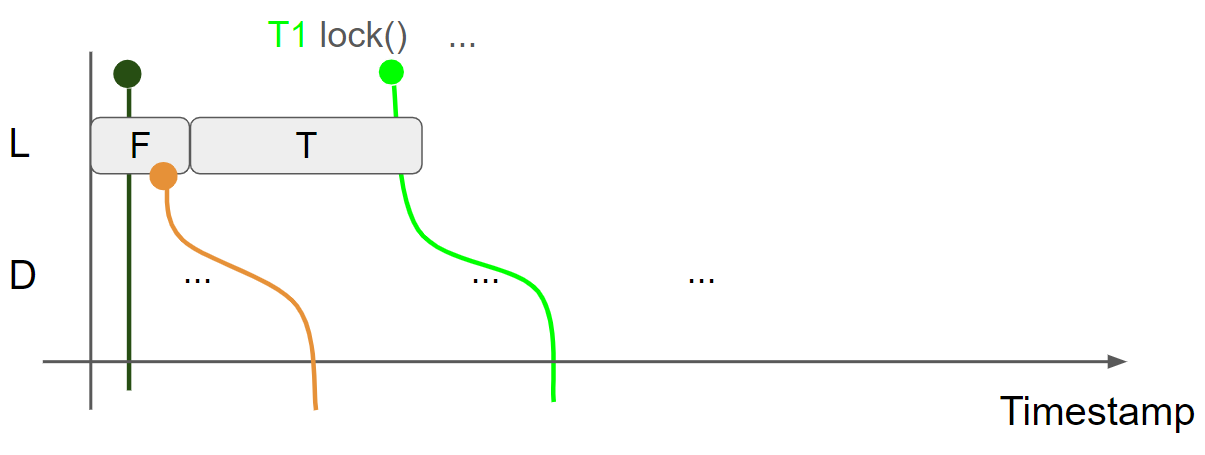
线程2调用 lock 函数获取锁,由于 L = F message 已经被邻接了,只能读到 L = T message,因此 cas 操作失败,进入 while 循环自旋,由于使用了 acquire,message view 会合并到线程2的 view 中,线程2的 view 变为 L = T & D = Something1:
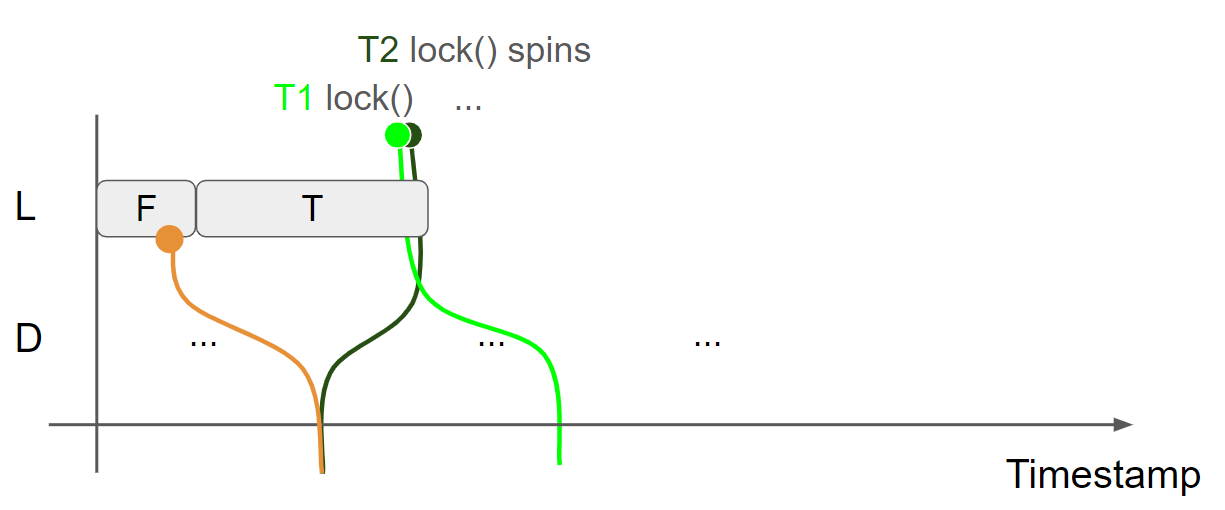
线程1调用 unlock 函数释放锁,执行 store(false, release) 操作,插入 L = F message,线程1的视图变为 L = F & D = Something2,由于使用了 release,会生成 message view:L = F & D = Something2:
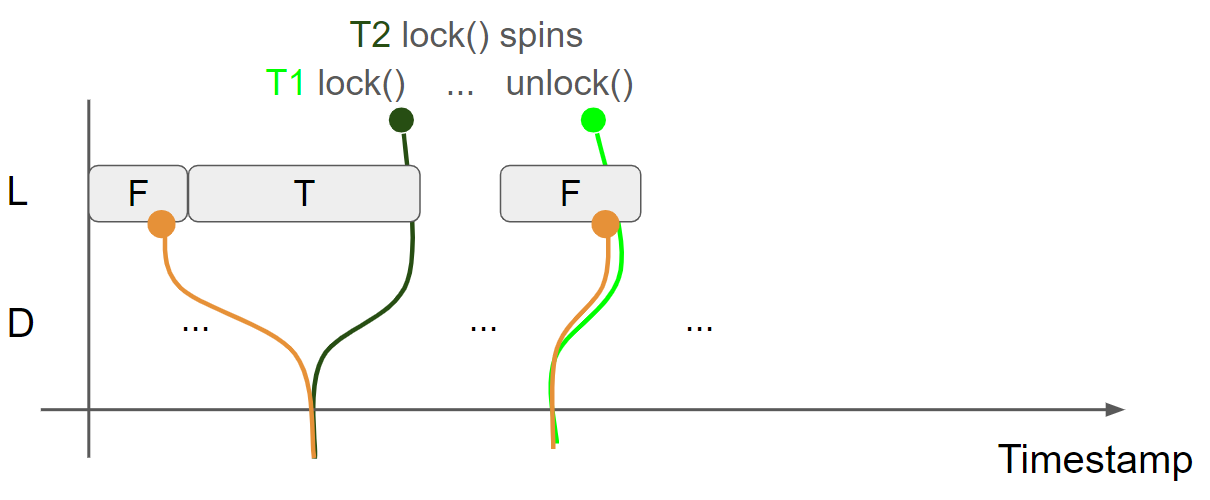
线程2调用 lock 函数获取锁,执行 cas(false, true, acquire) 操作,假设读到第二个 L = F message,因此 cas 操作执行成功,邻接 L = T message,由于使用了 acquire,message view 会合并到线程2的 view 中,线程2的 view 变为 L = T & D = Something2:
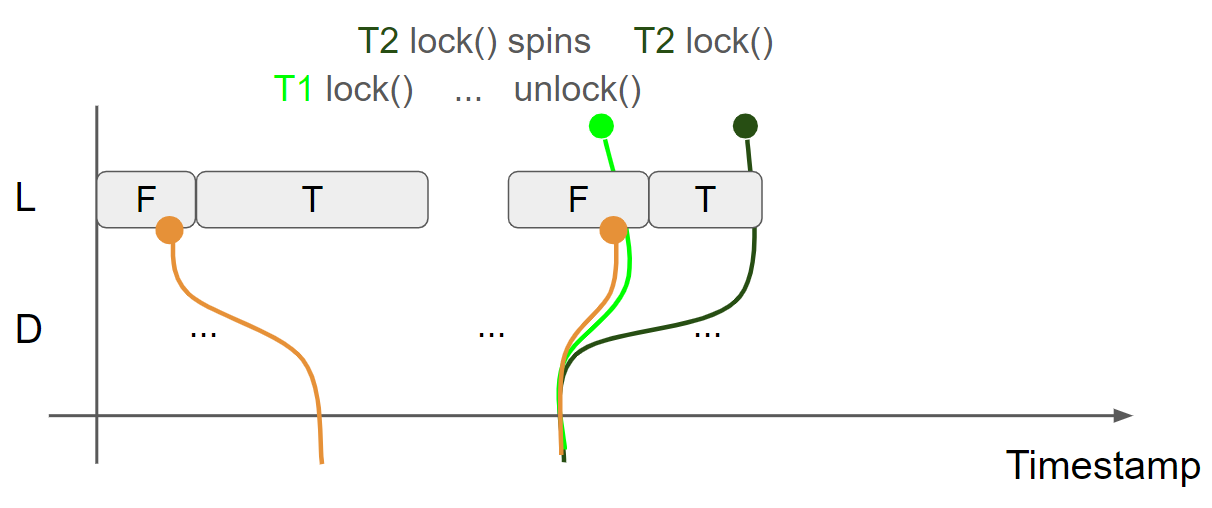
线程2持有锁,并修改 D,插入 D = Something3 message,线程2的view 变为 L = T & D = Something3:
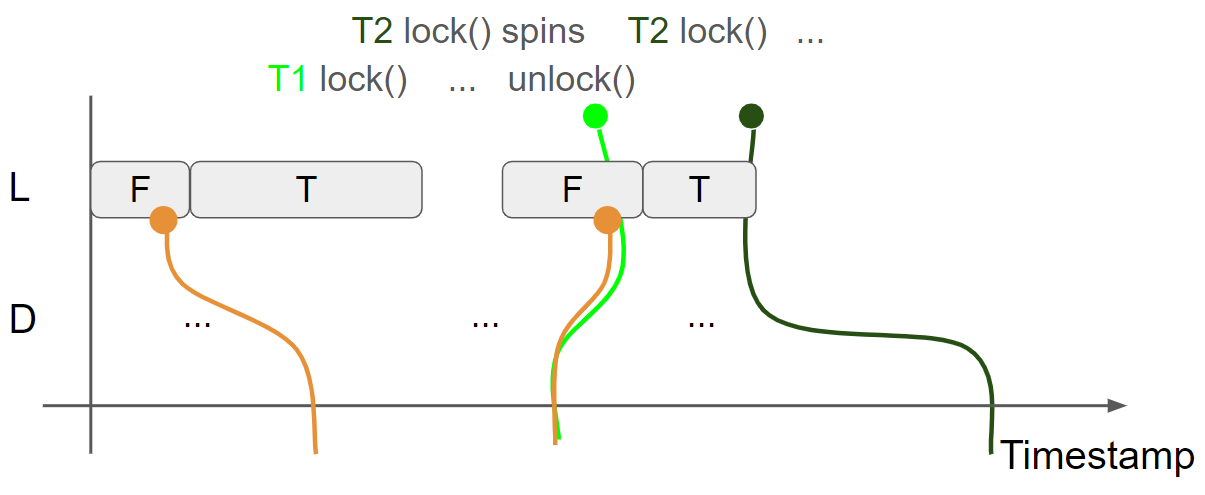
线程2调用 unlock 函数释放锁,执行 store(false, release) 操作,插入 L = F message,线程2的视图变为 L = F & D = Something3,由于使用了 release,会生成 message view:L = F & D = Something3:
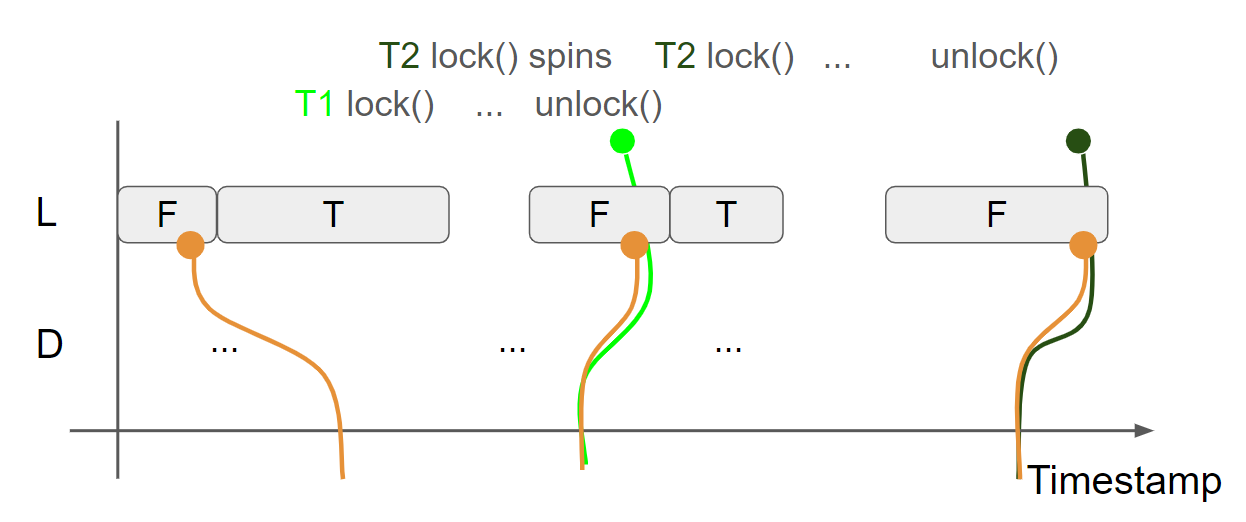
最后,全图执行流程如下所示:
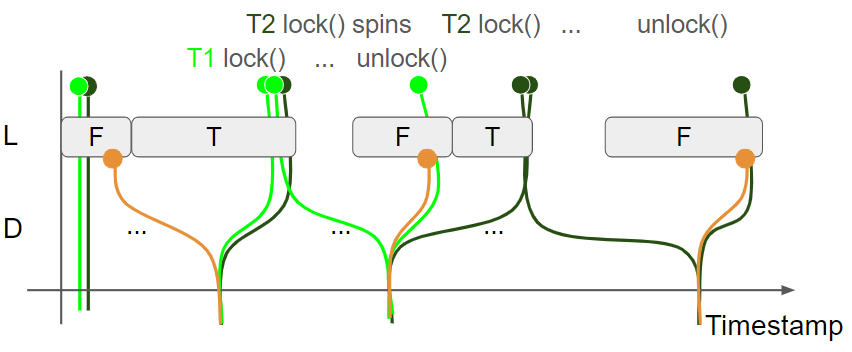
综上所述,线程1和线程2持有锁的 timestamp 区间不相交,因此多个线程不会同时读写锁保护的数据,并且当一个线程持有锁时,另一个线程尝试获取锁则会进入自旋。此外,通过 Release/Acquire 实现了 message passing,保证当一个线程持有锁时,访问到的是最新的数据。
Ticket lock
Ticket lock 代码:https://github.com/kaist-cp/cs431/blob/main/src/lock/ticketlock.rs。关键方法:
1 | |
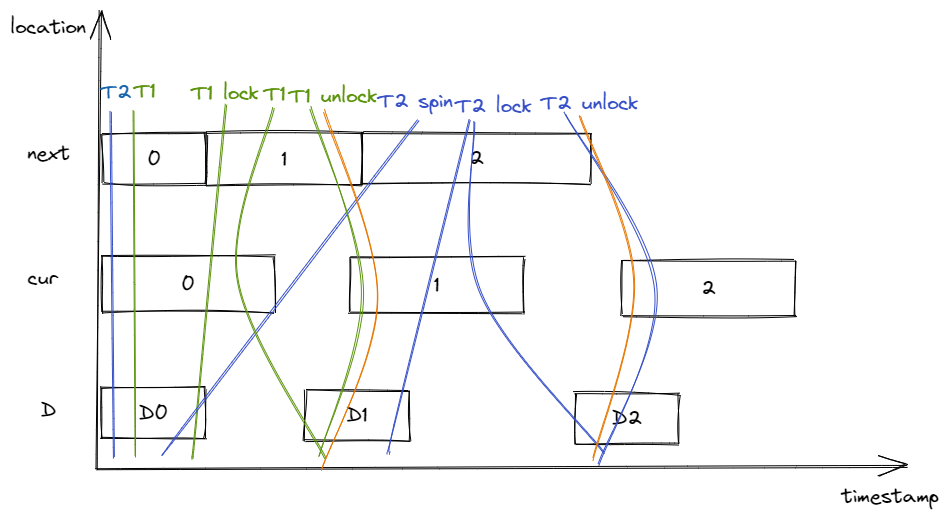
D 表示被锁保护的数据,绿色线条表示线程1,蓝色线条表示线程2。初始状态下,线程1的 view 为 next = 0 & cur = 0 & D = D0,线程的 view 为 next = 0 & cur = 0 & D = D0。执行流程描述如下:
- 线程1执行
self.next.fetch_add(1),读取 next = 0 message,邻接 next = 1 message,获取 ticket = 0。接着执行self.curr.load,读取 cur = 0 message,因为 cur = ticket = 0,因此结束循环,返回 ticket,线程1的视图最终变为 next = 1 & cur = 0 & D = D0; - 线程2执行
self.next.fetch_add(1),读取 next = 1 message,邻接 next = 2 message,获取 ticket = 1。接着执行self.curr.load,读取 cur = 0 message,因为 cur != ticket,因此开始自旋,线程2的视图更新为 next = 2 & cur = 0 & D = D0; - 线程1修改 D,插入 D = D1 message,线程1的视图更新为 next = 1 & cur = 0 & D = D1;
- 线程1释放锁,执行
self.curr.store(ticket.wrapping_add(1), Release),插入 cur = 1 message,线程1的视图更新为 next = 1 & cur = 1 & D = D1。因为使用了 Release,生成 message view:next = 1 & cur = 1 & D = D1; - 线程2执行
self.curr.load(Ordering::Acquire),假设读到 cur = 1 message,此时 cur = ticket = 1,因此结束循环,返回 ticket,线程2的视图更新为 next = 2 & cur = 1 & D = D0。因为使用了 Acquire,把 message view 合并到线程2的view中,线程2的视图变为 next = 2 & cur = 1 & D = D1; - 线程2修改 D,插入 D = D2 message,线程2的视图更新为 next = 2 & cur = 1 & D = D2;
- 线程2释放锁,执行
self.curr.store(ticket.wrapping_add(1), Release),插入 cur = 2 message,线程2的视图更新为 next = 2 & cur = 2 & D = D2。因为使用了 Release,生成 message view:next = 2 & cur = 2 & D = D2。
综上所述,线程1和线程2持有锁的 timestamp 区间不相交,当一个线程持有锁时,另一个线程尝试获取锁会进入自旋。此外,通过 Release/Acquire 实现了 message passing,保证当一个线程持有锁时,访问到的是最新的数据。
Clh lock
Clh lock 代码:https://github.com/kaist-cp/cs431/blob/main/src/lock/clhlock.rs。关键方法:
1 | |
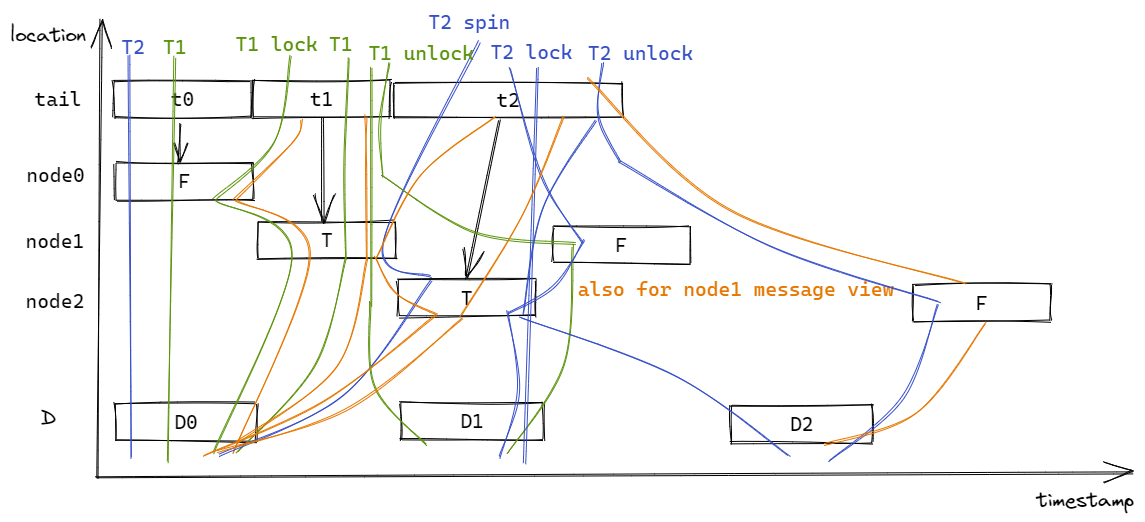
D 表示被锁保护的数据,绿色线条表示线程1,蓝色线条表示线程2。初始状态下,线程1的 view 为 tail = t0 & node0 = F & D = D0,线程2的 view 为 tail = t0 & node0 = F & D = D0。执行流程描述如下:
- 线程1调用lock函数,创建 node1,插入 node1 = T message。线程1执行
self.tail.swap(node1, AcqRel),读取 tail = t0 message,邻接 tail = t1 message,线程1的视图更新为 tail = t1 & node0 = F & node1 = T & D = D0。由于使用了 AcqReq,生成 tail = t1 的message view:tail = t1 & node0 = F & node1 = T & D = D0。线程1执行(*node0).locked.load(Ordering::Acquire),读取 node0 = F message,退出 while 循环。线程1执行drop(unsafe { Box::from_raw(node0) }),此时 node0 不会再有线程方法它,因此可以把 node0 相关的 message 从线程视图中删除,线程1 view 更新为 tail = t1 & node1 = T & D = D0, tail = t1 的message view 更新为 tail = t1 & node1 = T & D = D0。线程1 返回 Token(node1),此时线程1成功获取锁; - 线程2调用lock函数,创建node2,插入 node2 = T message。线程2执行
self.tail.swap(node2, AcqRel),读取 tail = t1 message,邻接 tail = t2 message,由于使用使用了 AcqRel,因此将 tail = t1 message view合并到线程2的视图中,线程2的视图更新为 tail = t2 & node1 = T & node2 = T & D = D0,同时生成 tail = t2 message view:tail = t2 & node1 = T & node2 = T & D = D0。线程2执行(*node1).locked.load(Ordering::Acquire),读取 node1 = T message,进入自旋; - 线程1修改 D,插入 D = D1 message,线程1的视图更新为 tail = t1 & node1 = T & D = D1;
- 线程1释放锁,执行
(*node1).locked.store(false, Release);,插入 node1 = F message,线程1的视图更新为 tail = t1 & node1 = F & D = D1。因为使用了 Release,生成 node1 = F message view:tail = t1 & node1 = F & D = D1; - 线程2执行
(*node1).locked.load(Ordering::Acquire),假设读到 node1 = F message,则退出循环,由于使用了 Acquire,将 node1 = F message view 合并线程2的 view中,线程2的视图更新为 tail = t2 & node1 = F & node2 = T & D = D1。线程2执行drop(unsafe { Box::from_raw(node1) }),此时 node1 不会再有线程方法它,因此可以把 node1 相关的 message 从线程视图中删除,线程2 view 更新为 tail = t2 & node2 = T & D = D1, tail = t2 的message view 更新为 tail = t2 & node2 = T & D = D1。线程2 返回 Token(node2),此时线程2成功获取锁; - 线程2修改 D,插入 D = D2 message,线程2的视图更新为 tail = t2 & node2 = T & D = D2;
- 线程2释放锁,执行
(*node2).locked.store(false, Release);,插入 node2 = F message,线程2的视图更新为 tail = t2 & node2 = F & D = D2。因为使用了 Release,生成 node2 = F message view:tail = t2 & node2 = F & D = D2。
综上所述,线程1和线程2持有锁的 timestamp 区间不相交,当一个线程持有锁时,另一个线程尝试获取锁会进入自旋。此外,通过 Release/Acquire 实现了 message passing,保证当一个线程持有锁时,访问到的是最新的数据。