Fault-tolerant Key/Value Service(一)
LAB 3:分布式KV
6.824 LAB 3的内容是基于LAB 2实现的Raft库构建一个容错的Key/Value服务。
容错的Key/Value服务是一个复制状态机,由多个使用Raft进行复制的Key/Value服务器组成。由于底层使用Raft实现复制,因此只要过半服务器没有故障并且能够互相通信,那么构建的Key/Value服务就能够一直处理客户请求。整体架构如图所示:
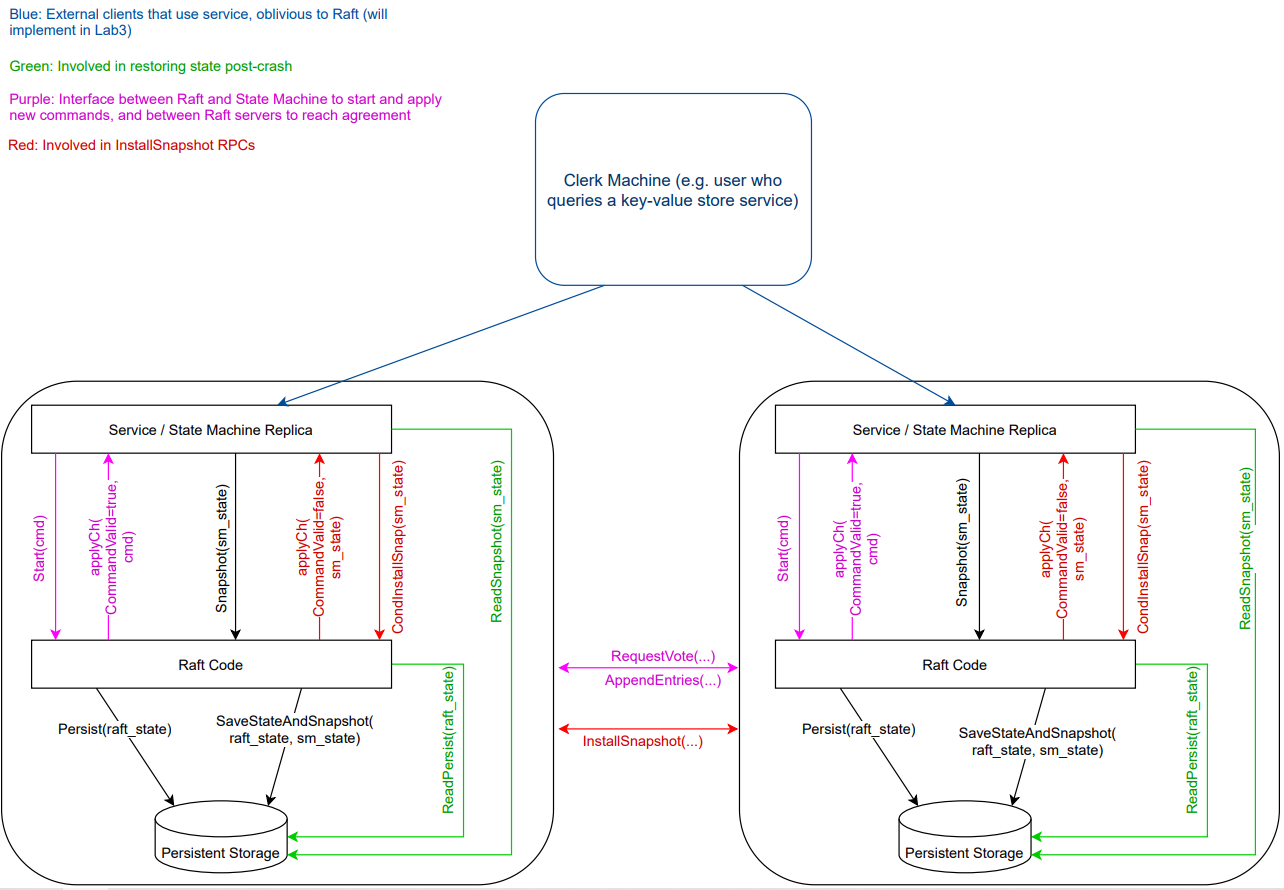
客户端可以向Key/Value服务发送三种不同的RPC:
Put(key, value):替换数据库中某一特定Key对应的Value。
Append(key, arg):将arg附加到Key对应的Value上。
Get(key):获取Key对应的Value。对于一个不存在的Key,Get应该返回一个空字符串。
每个客户端通过Clerk的Put/Append/Put方法与服务进行通信,Clerk负责管理与服务的RPC交互。
LAB 3要求客户端对Clerk的Get/Put/Append方法的调用是可线性化的。如果一次调用一个,Get/Put/Append方法应该表现得像系统只有一个副本一样,并且每次调用都应该观察到前面的调用序列对状态的修改(一个操作只能执行一次)。对于并发调用,返回值和最终状态必须与操作按某种顺序一次执行一个得到的结果相同。如果调用在时间上重叠,就是并发的:例如,如果客户端X调用Clerk.Put(),客户端Y调用Clerk.Append(),然后客户端X的调用返回。一个调用必须观察到在该调用开始之前已经完成的所有调用的效果。
实现线性一致性
由于使用Raft实现复制,写操作已经实现了线性一致性,因为所有的服务器都会按照相同的顺序执行相同的写操作:

对于读操作,我们可以把客户端的Get请求只发送到Leader,来确保一定能够读到最近写入的值。但是这样需要额外的机制来验证这个Leader是否是真的Leader,因为一个困在分区中的Leader是一个假Leader。
可以把读操作也提交到Raft日志中,这样所有的读写操作在所有的服务器中都会按照相同的顺序执行,并且读操作一定能够看到它之前的写操作写入的值。这种方法的缺点是性能差,为了把读操作的日志复制给大多数服务器,至少需要发送一轮AppendEntries RPC,需要花费10MS以上的时间。
过滤重复请求
当一个客户端向Key/Value服务器发送一个请求后,在超时时间内这个服务器可能执行不完这个请求,服务器会返回一个error给客户端,之后客户端会重新发送这个请求。因此,客户端可能会发送多条重复的请求给服务端。
这种情况下,服务器需要有能力过滤掉重复的请求,确保每个请求只执行一次。否则,服务器执行重复请求可能会导致状态的错误更改,导致违反线性一致性。
比如,客户端X向服务器发送请求 Append("K", "Hello"),之后由于一些原因客户端X再次发送请求 Append("K", "Hello"),如果服务器不过滤掉重复的请求,那么 K 对应的 Value 就会变为 HelloHello。但是在客户端看来,我只想要追加一个 Hello,最终却追加了两个,这显然不符合要求。
解决方法是在客户端存储一个客户端标识符和请求ID,并在服务端存储一张表,表中的每一项是客户端的标识符和对应的请求ID,请求ID是一个从1开始的递增整数。客户端每次发送请求时都把请求ID加一,然后把客户端标识符和请求ID附加到发送的请求中;服务器收到这个请求后可以查看这个客户端对应的最大请求ID,只有当发送过来的请求ID大于服务器存储的最大请求ID才执行这个请求,否者说明是一个重复的请求,直接返回即可。
LAB 3A中遇到的问题
架构理解错误
在实现LAB 3A的是否遇到的第一个问题就是把架构理解错了。在我原先的理解中,系统中只存在一个Clerk,然后存在多个客户端,所有的客户端都调用同一个Clerk的Put/Append/Get方法,因此对Clerk的调用是并发的:
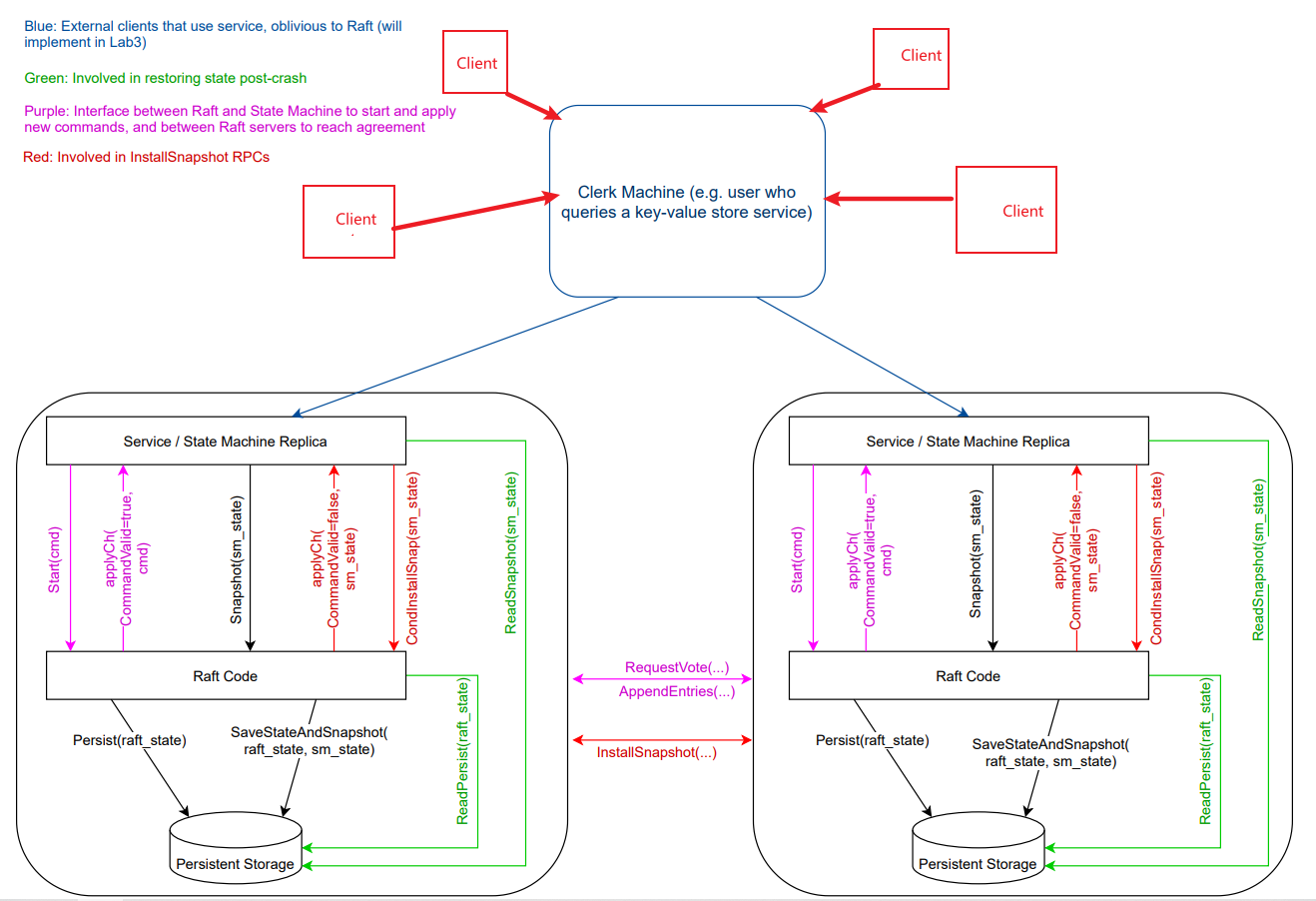
但是,这样的话无法知道是谁调用的Put/Append/Get方法,因为这些方法中没有客户端ID这个参数。我原来的想法是Clerk每次发送请求之前先生成一个随机的请求ID,之后发送请求时附带上这个ID。这样服务端在执行完一条请求后就可以把这个请求ID和执行结果存储在一条表中,之后如果客户端发送了一条重复的请求,我们就可以根据请求ID直接把结果返回,而不需要再次执行。
这个方法的问题随着请求的执行,服务端存储的请求ID和执行结果会越来越多,而且没有什么有效的清理无用数据的方法。
想了半天没啥好的思路,我就看了一下别人的LAB 3的实现文档,才发现我把LAB 3的架构理解错了。正确的架构是,有多个客户端,并且每个客户端有自己的Clerk,每个客户端阻塞调用自己的Clerk的Put/Append/Get方法:
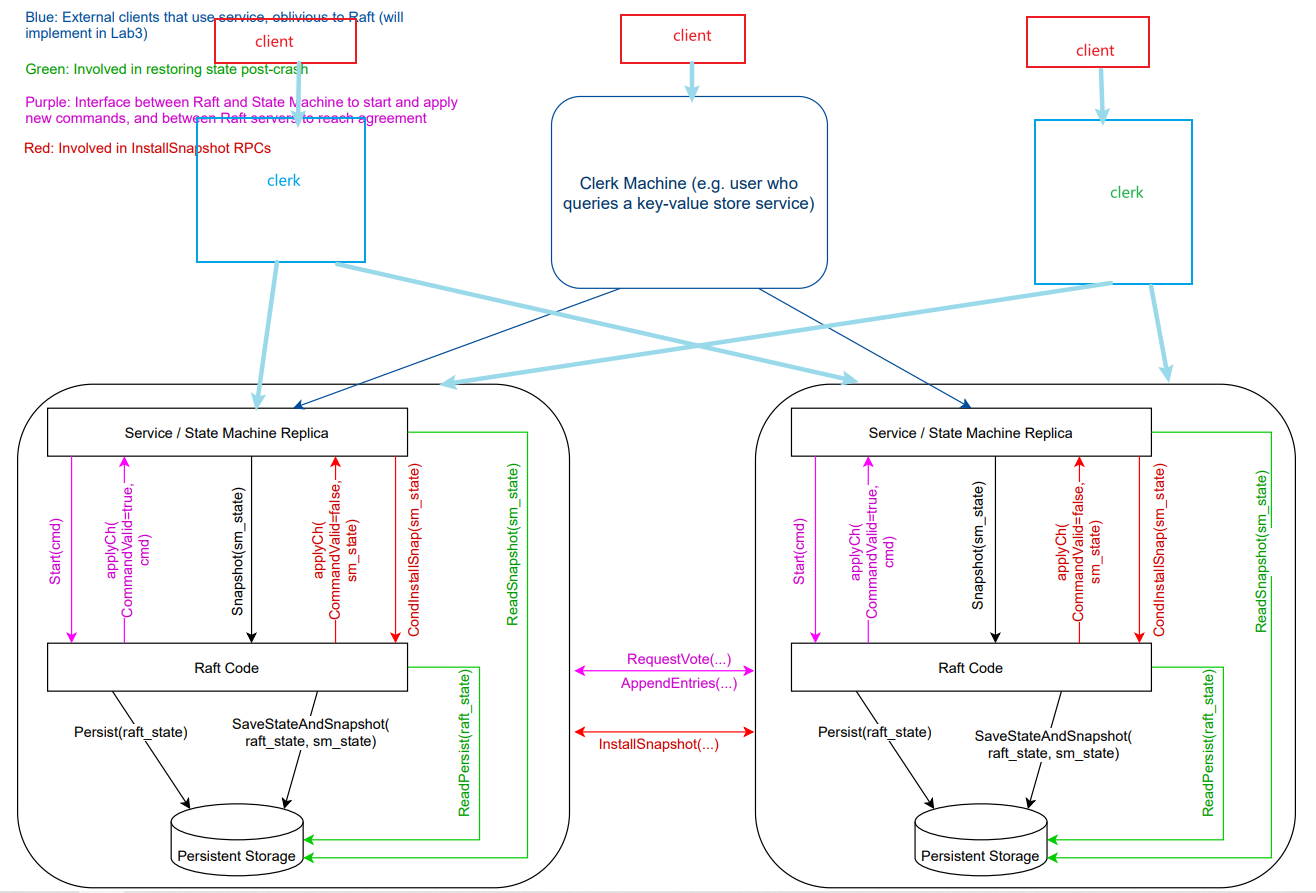
这样,就能够使用上面提到的过滤重复请求的方法了。
Bug 1
第一个遇到的问题是每条请求的执行时间过长,超过了33ms:
1 | |
我反复检查了LAB 3A的代码实现,都没找到啥问题,去网上搜了一下才发现是LAB2的实现策略有问题。
在我的LAB 2的实现中,心跳的间隔是100MS,并且只在心跳的是否才发送日志给其他的节点。如果只有一个客户端,客户端发送Put/Append/Get请求给服务器,服务器把这个请求提交给Raft,Raft需要等待100MS然后发送附加日志给其他的节点,之后才能提交执行这个请求,当服务器执行完这个请求后返回响应给客户端,之后客户端才能继续发起新的请求。因此,执行一条请求至少需要100MS,这没有达到33MS的要求。
解决方法很简单,在Raft执行Start方法添加完一条日志后,就立马发送心跳,这样就不需要等待100MS了。
Bug 2
第二个Bug是与Go语言相关的。如果向nil管道发送值会发生死锁,发送端Go程会被永久阻塞。最开始我的实现是这样的:
1 | |
如果当前的服务器不是Leader,那么command.Ch就等于nil,因此在发送前需要加一个判断:
1 | |
Bug 3
第三个Bug还是与Go语言相关的。对于一个同步管道,只有当接收方准备接收的时候,发送方才能发送过去,否则发送方会永久阻塞。最开始我的实现是这样的:
1 | |
如果在kv.waitTimeOut内还没有收到请求完成的通知,服务器会直接返回一个error给客户端。之后当请求完成后,执行command.Ch <- sendVal就会发生永久阻塞,因为此时已经没有接收方了。
解决方法是,在发送端也设置一个超时,如果在超时时间内没有发送成功就直接退出:
1 | |
解决完所有Bug后,并发跑500次测试:
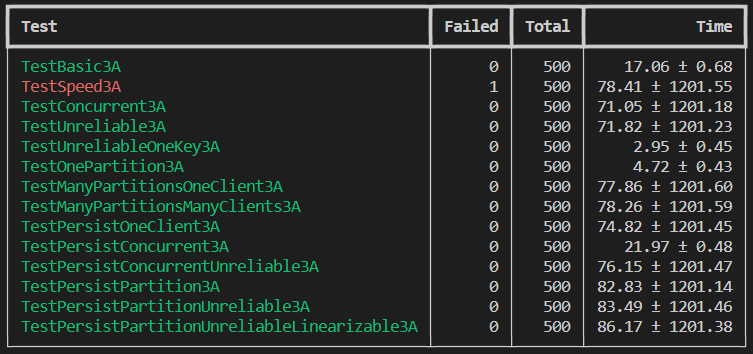
TestSpeed3A有一次测试没有通过,错误日志中显示每条操作花了37MS,没有达到33MS/op的要求,但是这个问题应该已经在Bug 1中被解决了。测试报告中显示,TestSpeed3A平均花费了78.41秒才完成,但是在单独测试中只花了10.9秒就完成了:

我就猜测可能是测试的时候开的线程太多导致的,毕竟我的电脑性能不太行。那么,只开5个线程并发跑500次TestSpeed3A测试:
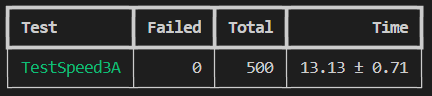
所有的测试全部通过,并且平均只花费了13.13秒。