Raft 持久化 Raft 中所有服务器需要持久化存储的状态:
参数
含义
currentTerm
服务器已知最新的任期(在服务器首次启动时初始化为0,单调递增)
votedFor
当前任期内收到选票的 candidateId,如果没有投给任何候选人则为空
log[]
日志条目;每个条目包含了用于状态机的命令,以及领导人接收到该条目时的任期(初始索引为1)
当服务器改变了被标记为持久化的某个数据时,服务器应该将更新写入到磁盘或其他持久化存储中。这样当服务器故障重启后,就可以从持久化存储中找到相应的数据并将其加载到内存中,恢复之前的状态。
currentTerm 持久化 currentTerm 需要被持久化存储是为了确保选举安全特性,即一个任期内最多只有一个 Leader 会被选举出来。
假设一共有三台服务器A、B、C。A是Leader,A有三条日志,其任期号分别为5、6、7;B有一条日志,任期号为5;C有一条日志,任期号为5。
这时,A还没复制日志给B、C,然后A、B、C都崩溃了。之后B、C重启,B、C需要选举出一个Leader,但是由于没有持久化 currentTerm,因此B、C不知道当前的任期号是多少,一种可能的方法是B、C通过查看自己的最后一条日志发现任期号为5,于是就会递增任期号并在任期6中选出一个Leader。
但是6是一个旧的任期号,在之前的这个任期中已经选举出了一个Leader了,这样一个任期中就选出了两个Leader,因此违反了选举安全特性。
votedFor 持久化 votefFor 需要被持久化存储也是为了确保选举安全特性。
假设一共有三台服务器A、B、C。A收到了B发来的投票请求,这时A检查发现自己的 votedFor 为空,于是给B投票。
然后A马上就崩溃重启了,这时收到C发来的投票请求,由于 votedFor 没有被持久化存储,因此B检查发现自己的 votedFor 为空,然后也会给C投票。这样B、C都收到了过半数的投票,B、C都会成为 Leader,这就违反了选举安全特性。
log[] 持久化 日志需要被持久化存储是因为在崩溃重启后,应用程序可以根据保存的日志条目来重建崩溃前的运行状态。
假设由于断电或者其他原因导致所有的服务器全都重启了,这时所有的服务器都没有任何关于之前的日志条目信息,这样的话就不可能恢复到崩溃前的运行状态了。
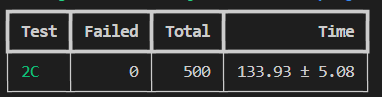
LAB 2C 中遇到的问题 最后说一说,在实现 6.824 的 LAB 2C 的过程中遇到的两个 Bug。
Bug 1 遇到的第一个Bug的错误日志如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 S1 starts election 40 to 41 for S1 40 to 41 for S1 40 to 41 40 to 41 for S3 41 to 42 for S0 41 to 42 for S0 41 to 42 41 to 42 for S3 42 to 43 for S1 42 to 43 42 to 43 for S1
在这个场景中,S0、S1和S2在一个网络分区中,S3 和 S4 分别在一个网络分区中。S0、S1的日志没有S2的日志新。
从日志中可以看到,S1总是先发起选举,然后S2收到S1的投票请求后会转化为跟随者,S2会重置自己的选举计时器,这就导致S2一直无法发起选举投票。
解决方法是,在收到投票请求时,如果需要转化为跟随者,则不重置选举计时器:
1 2 3 4 5 6 7 8 9 10 11 12 13 if args.Term > rf.currentTerm {false )func (rf *Raft) int , resetFlag bool ) {if resetFlag {go rf.ticker()
这样,即使S2在收到S1的投票请求后转化为跟随者,也不会重置选举超时计时器,在一定时间后S2将能够发起选举投票。
Bug 2 遇到的第二个Bug的错误日志如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 018750 LEAD S2 sends hearbeat018750 INFO S2 sends hearbeat to S4: &{Term:4 LeaderId:2 PrevLogIndex:2 PrevLogTerm:3 Entries:[{Command:2420 Term:4 CommandIndex:3 } {Command:6554 Term:4 CommandIndex:4 } {Command:6316 Term:4 CommandIndex:5 } {Command:648 Term:4 CommandIndex:6 } {Command:3226 Term:4 CommandIndex:7 } {Command:9916 Term:4 CommandIndex:8 } {Command:6121 Term:4 CommandIndex:9 } {Command:9155 Term:4 CommandIndex:10 } {Command:9102 Term:4 CommandIndex:11 } {Command:1911 Term:4 CommandIndex:12 }] LeaderCommit:0 }018752 INFO S2 sends hearbeat to S0: &{Term:4 LeaderId:2 PrevLogIndex:2 PrevLogTerm:3 Entries:[{Command:2420 Term:4 CommandIndex:3 } {Command:6554 Term:4 CommandIndex:4 } {Command:6316 Term:4 CommandIndex:5 } {Command:648 Term:4 CommandIndex:6 } {Command:3226 Term:4 CommandIndex:7 } {Command:9916 Term:4 CommandIndex:8 } {Command:6121 Term:4 CommandIndex:9 } {Command:9155 Term:4 CommandIndex:10 } {Command:9102 Term:4 CommandIndex:11 } {Command:1911 Term:4 CommandIndex:12 }] LeaderCommit:0 }018753 INFO S2 sends hearbeat to S1: &{Term:4 LeaderId:2 PrevLogIndex:2 PrevLogTerm:3 Entries:[{Command:2420 Term:4 CommandIndex:3 } {Command:6554 Term:4 CommandIndex:4 } {Command:6316 Term:4 CommandIndex:5 } {Command:648 Term:4 CommandIndex:6 } {Command:3226 Term:4 CommandIndex:7 } {Command:9916 Term:4 CommandIndex:8 } {Command:6121 Term:4 CommandIndex:9 } {Command:9155 Term:4 CommandIndex:10 } {Command:9102 Term:4 CommandIndex:11 } {Command:1911 Term:4 CommandIndex:12 }] LeaderCommit:0 }018754 INFO S2 sends hearbeat to S3: &{Term:4 LeaderId:2 PrevLogIndex:2 PrevLogTerm:3 Entries:[{Command:2420 Term:4 CommandIndex:3 } {Command:6554 Term:4 CommandIndex:4 } {Command:6316 Term:4 CommandIndex:5 } {Command:648 Term:4 CommandIndex:6 } {Command:3226 Term:4 CommandIndex:7 } {Command:9916 Term:4 CommandIndex:8 } {Command:6121 Term:4 CommandIndex:9 } {Command:9155 Term:4 CommandIndex:10 } {Command:9102 Term:4 CommandIndex:11 } {Command:1911 Term:4 CommandIndex:12 }] LeaderCommit:0 }018764 VOTE S2 receives VoteRequestRpc from S3018764 INFO S2 becomes Follower018764 TERM S2 changes term from 4 to 5 018866 VOTE S2 starts election018867 INFO S2 becomes Candidate018867 TERM S2 change term from 5 to 6 018867 VOTE S2 votes for S2018869 VOTE S1 receives VoteRequestRpc from S3018869 TERM S1 changes term from 4 to 5 018870 VOTE S1 votes for S3018988 INFO S3 receives AppendEntriesRpc from S2018988 INFO S3 reply AppendEntriesRpc from S2: &Reply{Term: 5 , Success: false }018992 VOTE S3 receives VoteRequestRpc from S2018992 INFO S3 becomes Follower018992 TERM S3 changes term from 5 to 6 018992 VOTE S3 votes for S2019029 VOTE S1 receives VoteRequestRpc from S2019029 TERM S1 changes term from 5 to 6 019029 VOTE S1 votes for S2019032 INFO S2 becomes Leader019032 LEAD S2 sends hearbeat019033 INFO S2 sends hearbeat to S4: &{Term:6 LeaderId:2 PrevLogIndex:12 PrevLogTerm:4 Entries:[] LeaderCommit:0 }019035 INFO S1 receives AppendEntriesRpc from S2019035 INFO S1 reply AppendEntriesRpc from S2: &Reply{Term: 6 , Success: false }panic : runtime error : index out of range [-1 ]
这是一个由于负数索引导致的运行崩溃错误,代码如下所示(在第20行崩溃):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 rf.mu.Lock()if rf.role != LEADER {return if reply.Term < rf.currentTerm {return if reply.Term > rf.currentTerm {true )return if !reply.Success {if reply.XTerm == -1 {1 else if reply.XTerm == rf.log[reply.XIndex-1 ].Term {1 else {else {
在我的实现中只有三种情况 reply.Success = false:
节点已经被Kill了,这时候会返回 reply.Term = 0
收到的心跳的任期号比当前节点的任期号小,这时候会返回 reply.Term=XX
收到的心跳的prevLogIndex位置的日志不匹配,这时候会返回 reply.XTerm=-1 或 reply.XIndex=YY
第一种情况,第八行的代码会将其排除。第二种情况,第十二行代码会将其排除。第三种情况,如果要走到第20行,则只能是 reply.XIndex=YY,但是我的实现中 YY 一定大于0。这样,所有情况都排除了,那么为什么会出现这个问题呢?
通过观察日志可以发现,在第四行,S2给S1发送了一个心跳:
1 S2 sends hearbeat to S1: &{Term:4 , ......}
此时S2的任期号为4。从第四行到第25行,S2先是变成了Follower,之后又在任期6被选举成为Leader。
在第28行,S1终于收到了S2发送的心跳,此时S1的保存的任期号为6,因此它会返回 Reply{Term: 6, Success: false, XIndex=0}。这是前面提到的第二种情况,但是此时S2的任期号也变成了6,因此第十二行代码就无法排除这种情况。最终代码就会执行到第20行,导致运行时崩溃。
可见,这是由于网络延迟导致的错误,解决方法也很简单,在第20行代码之前在加一个判断,如果reply.XIndex=0则不执行后面的代码了:
1 2 3 4 5 6 7 8 9 if reply.XTerm == -1 {1 else if reply.XIndex != 0 {if reply.XTerm == rf.log[reply.XIndex-1 ].Term {1 else {
解决完上述的两个Bug后,并发跑500次测试,全部顺利通过:
参考