日志复制 具体的日志复制算法,在 Raft 论文中说的非常详细:Raft paper (第5节、5.3节)。
在 LAB 2B 的实现中需要施加选举限制:Raft paper (第5.4.1节)。
需要注意的是,Leader 只能提交当前任期内的日志:Raft paper (第5.4.2节)。
日志加速回退 在 Raft paper (第5节)中提到,如果 Leader 向一个 Follower 追加日志失败,就表明 Leader 和 Follower 的日志有冲突,则 Leader 会回退一个 Log,之后再次向跟随者追加日志。
假设有这样一个场景,我们有5个服务器,有1个 Leader,这个 Leader 和另一个 Follower 困在一个网络分区中。这个 Leader 一直向它唯一的 Follower 发送 AppendEntries,因为没有过半服务器,所以没有一条 Log 会 commit。在另一个有多数服务器的网络分区中,系统会选出新的 Leader 并继续运行。旧的 Leader 和它的 Follower 可能会记录无限多的旧的任期的未 commit 的 Log。当旧的 Leader 和它的 Follower 重新加入到集群中时,这些 Log 需要被删除并覆盖。
如果 Leader 每次只能在附加日志RPC 失败后回退一个 Log 然后重试的话,可能会耗费大量的时间。因此,需要某些方法来加速日志的回退。
6.824 的课堂上,Robert 教授给出了一个方法:让 Leader 可以每次回退一整个任期的 Log,而不是只回退一个 Log。
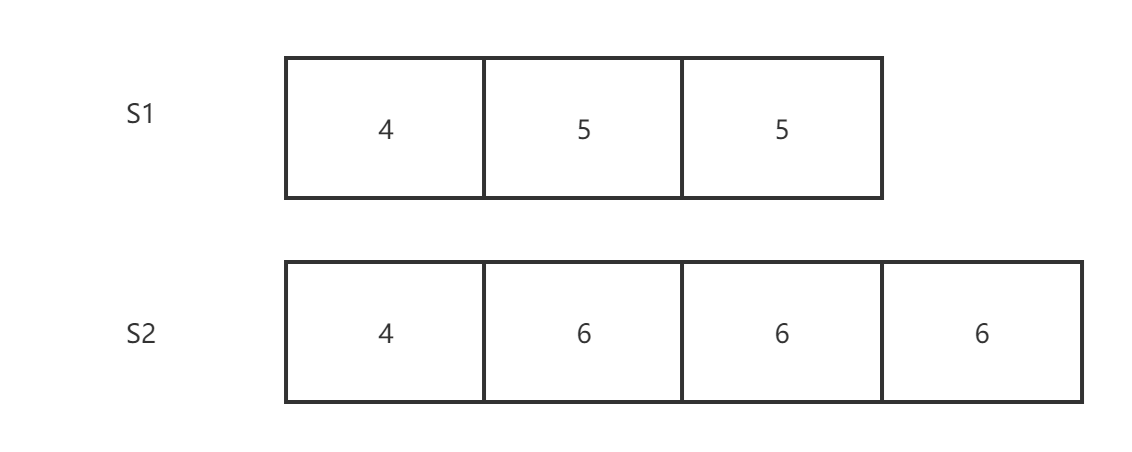
我们将可能的场景分成3类,在这里假设我们只有一个 Leader(S2)和一个 Follower(S1),S2 要发送一条任期号为6的 AppendEntries 消息给 S1:
(1)场景一
S1没有任期6的 Log,因此我们需要回退一整个任期的 Log。
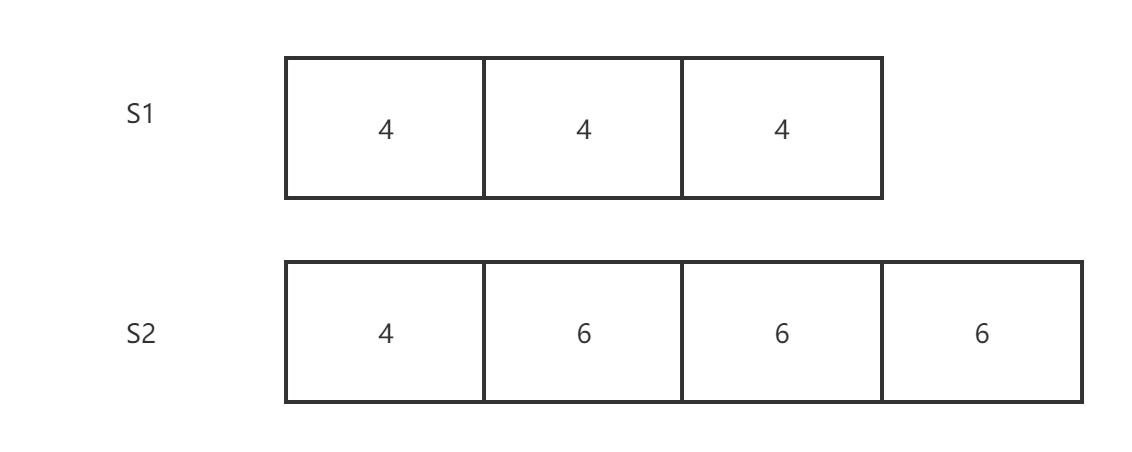
(2)场景二
S1 收到了任期4的旧 Leader 的多条 Log,但是作为新 Leader,S2 只收到了一条任期4的 Log。所以这里,我们需要覆盖 S1 中有关旧 Leader 的 Log。
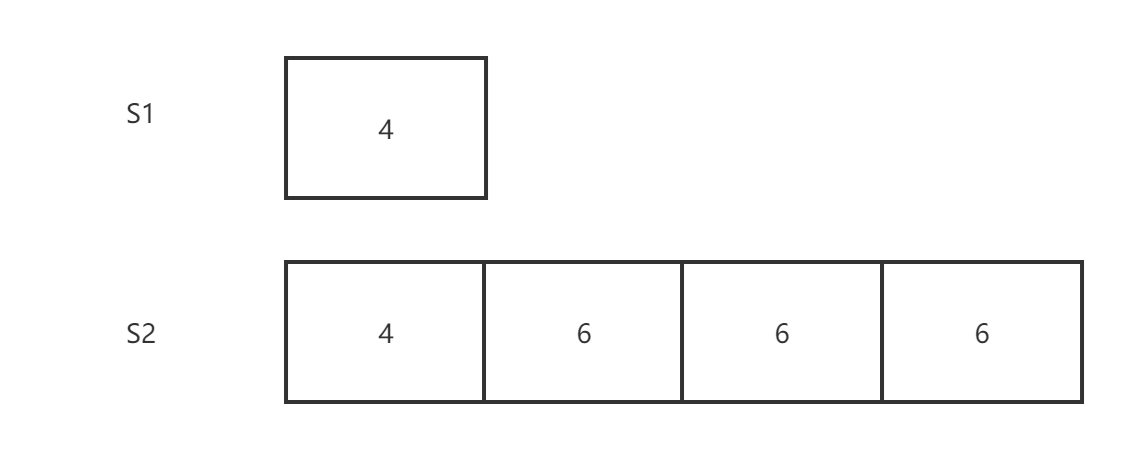
(3)场景三
S1 与 S2 的 Log 不冲突,但是 S1 缺失了部分 S2 中的Log,这里我们回退掉所有空缺的 Log。
可以让 Follower 在回复 Leader 的 AppendEntries 消息中,携带3个额外的变量,来加速日志的恢复:
XTerm:Follower 与 Leader 冲突的 Log 对应的任期号。如果 Follower 在 PrevLogIndex 位置的任期号与 Leader 不匹配,它会拒绝 Leader 的 AppendEntries 消息,并将自己的任期号放在 XTerm 中。如果 Follower 在对应位置没有 Log,那么这里会返回 -1。
XIndex:Folower 中任期号为 XTerm 的第一条 Log 的槽位号。
XLen:如果 Follower 在 PrevLogIndex 位置没有 Log,那么 XTerm 会返回-1,XLen 表示空白的 Log 槽位数。
Leader 收到错误返回时,就可以根据上述信息加速日志回退:
场景一:S1 会返回 XTerm=5,XIndex=2。S2 发现自己没有任期5的日志,它会将 S1 的 nextIndex 设置为 XIndex,也就是S1中,任期5的第一条Log对应的槽位号。
场景二:S1 会返回 XTerm=4,XIndex=1。S2 发现自己有任期4的日志,它会将 S1 的 nextIndex 设置为 XIndex+1。
场景三:S1 会返回 XTerm=-1,XLen=2。这表示 S1 中日志太短了,在冲突的位置没有 Log 条目,Leader 应该回退到 Follower 最后一条 Log 条目的下一条,也就是说 S2 会将 S1 的 nextIndex 设置为 nextIndex-XLen。
LAB 2B 中遇到的问题 最后说一说,在实现 6.824 的 LAB 2B 的过程中遇到的一些 Bug。
Bug 1 在运行 LAB 2B 的测试后,第一个没有通过的是测试 TestRPCBytes2B。错误日志如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 S0 starts running 0 to 1 for S2 1 to 1 for S2 1 to 1 for S2
在错误日志中,S2 连续两次成为 Leader,导致 S2 中运行了两个 heartbeat ticker,因此 S2 就会发送比正常的 Leader 的两倍字节数,所以无法通过 TestRPCBytes2B 测试。
根据错误原因,可以定位错误是在请求投票的实现中,代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 func (rf *Raft) 1 for i := range rf.peers {if i == rf.me {continue go func (peerId int ) if rf.role != CANDIDATE {return if !rf.sendRequestVote(peerId, args, reply) {return if reply.Term > rf.currentTerm {return if !reply.VoteGranted {return if receivedVotes*2 > len (rf.peers) {
我们把 Go 程中锁的使用分成两部分,第一部分:第10行(上锁)——第23行(解锁),第二部分:第29行(上锁)——第43行(解锁)。
假设所有的 Go 程都执行完第一部分后,再执行第二部分。这样所有的 Go 程都能发送请求投票RPC,因为此时当前的节点一定是跟随者。这样,当执行第二部分时,在得到的投票数达到半数服务器数量后,每多收到一票,就会调用 rf.convertToLeader() 转化为跟随者,从而导致上述的错误。
解决方法很简单,只需要在第二部分的开头增加一个对当前节点是否还是候选者的判断即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 func (rf *Raft) 1 for i := range rf.peers {if i == rf.me {continue go func (peerId int ) if rf.role != CANDIDATE {return if !rf.sendRequestVote(peerId, args, reply) {return if rf.role != CANDIDATE {return if reply.Term > rf.currentTerm {return if !reply.VoteGranted {return if receivedVotes*2 > len (rf.peers) {
Bug 2 遇到的第二个 Bug 是由于使用负数索引导致的运行时崩溃,报错如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 Test (2 A): initial election ...3.1 3 56 16914 0 2 A): election after network failure ...2022 /07 /30 18 :00 :11 0 1 2 0 0 0 panic : runtime error : index out of range [-1 ]230 [running]:6.824 /raft.(*Raft).sendHearbeat.func1(0xc0000c81e0 , 0x1 )6.824 /src/raft/raft.go :613 +0x66f 6.824 /raft.(*Raft).sendHearbeat6.824 /src/raft/raft.go :571 +0x64 2 6.824 /raft 3.157 s
索引越界具体发生在代码的613行:
1 if reply.XTerm == rf.log[reply.XIndex-1 ].Term
通过日志可以知道,发生错误时心跳 RPC 得到的返回消息是:
1 2 3 4 5 6 7 Reply {0 false 0 0 0
根据 Term=0 和 Success=false 可以看出跟随者似乎没有执行任何对心跳消息的处理就直接返回了。可以推断出,跟随者应该是已经”死掉“了,因此才没有执行对心跳消息的处理。
解决方法是,在发送心跳的函数中增加对跟随者节点状态的判断,代码如下:
1 2 3 4 if reply.Term < rf.currentTerm {return
只要 reply.Term 小于 Leader 的任期号,就可以知道跟随者没有对 Leader 发送的心跳进行处理,那么跟随者自然就已经”死掉了“。
Bug 3 第三个遇到的问题是 TestRejoin2B 测试失败,失败的日志如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 S0 sends hearbeat 2 : &{Term:3 0 PrevLogIndex:3 3 Entries:[] 3 } 1 : &{Term:3 0 PrevLogIndex:2 2 Entries:[{Command:104 3 CommandIndex:3 }] 3 } 2 to 3 3 Success:true XTerm:0 0 XLen:0 } int =104 ), Index: 3 } 2 to 3 105 2 CommandIndex:3 } 2 : &{Term:2 1 PrevLogIndex:1 1 103 Term:2 2 } {Command:105 2 CommandIndex:3 }] 2 } 3 , Success: false } 3 to 3 0 : &{Term:3 1 PrevLogIndex:2 2 105 Term:2 3 }] LeaderCommit:2 } 105 2 CommandIndex:3 }] 3 Success:true XTerm:0 0 XLen:0 }
在上面的日志中,S0 是 Leader 并且和 S2 可以正常通信,S1 被困在一个单独的网络分区中,并且自认为自己是 Leader。
当 S1 恢复正常后,S1 向 S2 发送 AppendEntries,然后收到了拒绝回复,并根据回复中的任期号重置自己的任期号,将自己转化为跟随者。到这里一切都还正常,但是接着 S1 继续向 S0 发送了 AppendEntries,导致 S0 退化成了跟随者,并且被追加了一条来自跟随者的日志,从而导致错误。
错误原因很明显,S1 在发送 AppendEntries 之前没有判断自己是否还是 Leader,因此在 S1 转变为跟随者之后,S1 仍然向 S0 发送了RPC消息。
那么,只需要在发送 AppendEntries 之前加一个小的条件判断即可:
1 2 3 4 5 if rf.role != LEADER {return
Bug 4 最后遇到的 Bug 是没有通过 TestFailNoAgree2B 测试,错误日志如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 S0 starts running 0 to 1 for S0 0 to 1 for S0 0 to 1 for S0 1 0 PrevLogIndex:0 0 Entries:[] 0 } 0 to 1 1 Success:true XTerm:0 0 XLen:0 } 1 0 PrevLogIndex:0 0 Entries:[] 0 } 1 Success:true XTerm:0 0 XLen:0 } 1 0 PrevLogIndex:0 0 Entries:[] 0 } 0 to 1 for S3 10 1 CommandIndex:1 } 1 0 PrevLogIndex:0 0 Entries:[{Command:10 1 CommandIndex:1 }] 0 } 10 1 CommandIndex:1 }] 1 Success:true XTerm:0 0 XLen:0 } 1 0 PrevLogIndex:0 0 Entries:[] 0 } 1 Success:true XTerm:0 0 XLen:0 } 1 0 PrevLogIndex:0 0 Entries:[{Command:10 1 CommandIndex:1 }] 0 } 10 1 CommandIndex:1 }] 1 Success:true XTerm:0 0 XLen:0 } 0 to 1 1 0 PrevLogIndex:0 0 Entries:[{Command:10 1 CommandIndex:1 }] 1 } 10 1 CommandIndex:1 }] 0 to 1 1 Success:true XTerm:0 0 XLen:0 } 1 0 PrevLogIndex:0 0 Entries:[{Command:10 1 CommandIndex:1 }] 1 } 10 1 CommandIndex:1 }] 0 to 1 1 Success:true XTerm:0 0 XLen:0 } 1 Success:true XTerm:0 0 XLen:0 } int =10 ), Index: 1 } 0 to 1 int =10 ), Index: 1 } 0 to 1 6.824 /raft.(*Raft).applyMsgToStateMachine(0xc0000e02d0 )6.824 /raft 0.767 s
在这个场景中,S0 收到了 S1 和 S2 的投票,在第20行成为了 Leader。之后 S0 在43行发送附加日志给 S3,附加日志的请求内容为:
1 2 S0 sends hearbeat to S1: &{Term:1 LeaderId:0 PrevLogIndex:0 0 Entries:[] LeaderCommit:0 }
之后,S0在51行收到了客户端的请求,并添加了一条日志:
1 S0 appends a log: {Command:10 Term:1 CommandIndex:1 }
接着,S0 在第109行将追加的日志发送给 S3:
1 2 3 4 S0 sends hearbeat to S3: &{1 LeaderId:0 PrevLogIndex:0 0 Entries:[{Command:10 Term:1 CommandIndex:1 }] 1 }
但是 S3 在第118行首先收到了第二条附加日志RPC:
1 2 3 4 S3 receives AppendEntriesRpc from S0 10 Term:1 CommandIndex:1 }] 0 to 1
S3 在125行才收到第一条附加日志RPC:
1 2 S3 receives AppendEntriesRpc from S0
由于RPC请求的乱序到达,S3 首先会收到第二条附加日志RPC,它会追加一条日志。之后才会收到一条附加日志RPC,这这个RPC的 Entries 是空的,这回导致 S3 覆盖掉之前追加的日志。
但是 S3 此时已经将 CommitIndex 修改为1,之后 S3 会应用 ComminIndex 位置的日志到状态机中,但是对应位置的日志是空的,这就导致了错误。
很明显,在收到第一条附加日志RPC后,我们不能覆盖掉之前的追加的日志,因此在追加日志的实现中应该加一些判断:
1 2 3 4 5 6 7 8 logIndex, entriesIndex := args.PrevLogIndex+1 , 0 for logIndex <= rf.lastLogIndex && entriesIndex < len (args.Entries) && rf.log[logIndex-1 ] == args.Entries[entriesIndex] {if !(entriesIndex == len (args.Entries) && logIndex <= rf.lastLogIndex && rf.log[logIndex-1 ].Term == args.Term) {append (rf.log[:logIndex-1 ], args.Entries[entriesIndex:]...)
首先,我们扫描发送过来的日志和本地的日志,找到第一条不匹配的日志的位置X。在之前的实现中,没有第6行的判断,直接执行第7行的追加日志操作,这可能导致已有的日志被覆盖。
如果剩下的需要追加的日志为空,并且X对应的位置存在日志,如果X对应的日志的任期与当前的 Leader 的任期号相等,说明X对应的日志是当前Leader发送过来的,那么就不应该覆盖掉它。
除了上述情况,都可以直接执行 rf.log = append(rf.log[:logIndex-1], args.Entries[entriesIndex:]...) 把剩下的日志复制过去。
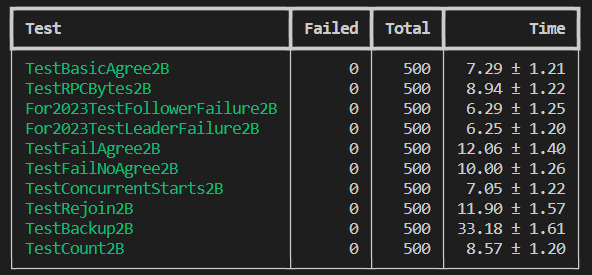
在解决完所有 Bug 后并发跑500次测试,全部顺利通过:
参考